(最終更新日: 2025年11月30日)
DifyのGUIでアプリは作れたけど、APIの全体像やOpenAIとの使い分けがわからない…そんな悩みはありませんか?
本記事は、Dify APIの考え方から手を動かす手順まで、現場目線でやさしく整理します。
認証や基本リクエスト、/chat-messagesでのチャット呼び出し、/workflows/runでの処理実行、/completion-messagesの使いどころを一気に把握できます。
ナレッジ連携やログ・エラー対応、料金の見積もり方、採用/非採用の判断軸も具体例付きで解説します。
読み終えるころには、社内ツールや自社プロダクトへ「まず動く」連携が自信をもって作れます。
実運用での学びと最新仕様を踏まえて、2025年版のベストプラクティスをお届けします。
Dify APIの全体像:他LLM APIとの違いと基本コンセプト
当セクションでは、Dify APIの基本コンセプトと他LLM APIとの違い、そして全体像を整理します。
理由は、Difyを「ただのLLMラッパー」と誤解すると設計判断を誤り、後戻りコストが大きくなるからです。
- Difyは「LLMのラッパー」ではなくAIバックエンド(BaaS)
- 2025年時点のDify APIでできること一覧
- OpenAI API等との役割分担:いつDifyを挟むべきか
Difyは「LLMのラッパー」ではなくAIバックエンド(BaaS)
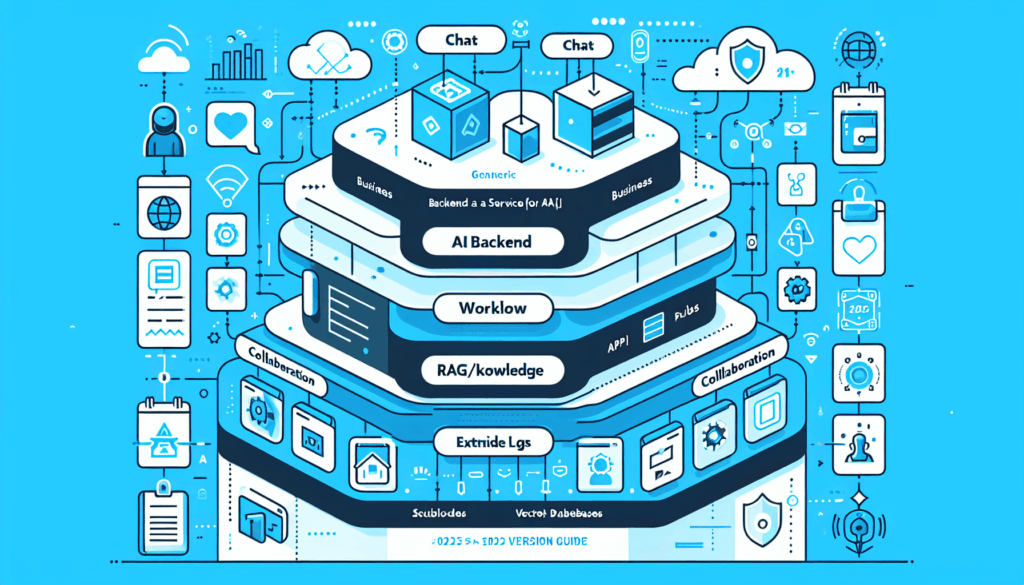
結論は、DifyはLLM単体を包むラッパーではなく、AI運用に必要な“バックエンド一式”をGUI+APIで提供するBaaSだということです。
なぜなら、モデル接続、ベクトルDB、RAGパイプライン、ワークフロー実行、ログ・分析、アクセス制御までを統合し、アプリ側からは単一APIで呼び出せるからです。
結果として「AIロジック(プロンプト、RAG、モデル選択)」と「アプリロジック(UI、業務ルール)」を分離し、プロダクトの変更に強い構成を保てます。
アーキテクチャのイメージは以下の通りです。

対照的に、ゼロからAIバックエンドを作る場合は次の要素が必要になりがちです。
- プロンプト管理とバージョニング、A/Bモデルトグル
- RAGのETL・チャンク設計・ヒットテスト・評価
- 会話状態・セッション管理とレート制御
- LLM呼び出しのリトライ/タイムアウト/エラー監視
- ログ集約・コスト/トークン監視・フィードバック収集
- 権限・鍵管理・監査ログ・データレジデンシー対応
これらをDifyは一体化して提供し、運用負荷と実装の分断を劇的に下げます(参考: Dify: Leading Agentic Workflow Builder)(参考: langgenius/dify-docs)。
2025年時点のDify APIでできること一覧
要点は、Dify APIは「チャット/エージェント」「シングルターン生成」「ワークフロー」「ナレッジ」「ログ/フィードバック」「外部ナレッジ」「プラグイン」を包括し、ビジネスシステムに直結できることです。
理由は、Dify Studioで設計したロジックをそのままRESTで呼べるため、PoCから本番まで同一面で運用できるからです。
まずは全体マップを押さえましょう。

| 機能カテゴリ | 代表エンドポイント/機能 | 典型ユースケース |
|---|---|---|
| チャット/エージェント | POST /chat-messages(blocking/streaming) | 社内FAQ、営業アシスタント、状態を保つ対話UX |
| シングルターン生成 | POST /completion-messages | 翻訳、要約、メール定型文生成 |
| ワークフロー実行 | POST /workflows/run | スクレイプ→要約→DB保存などのエージェンティック処理 |
| ナレッジ管理 | データセットAPI、ヒットテスト | RAG精度検証、ドキュメント継続投入 |
| フィードバック/履歴 | POST /messages/:id/feedbacks、履歴取得 | 品質改善、監査、ユーザー別KPI追跡 |
| 外部ナレッジ | External Knowledge API | 既存のElasticsearch/自社ベクトルDBを活用 |
| プラグイン(Endpoint) | Endpoint拡張(MCP連携予定含む) | 社内API/ERP連携、逆呼び出しで高度な自動化 |
どれを使うべきかは要件次第ですが、会話を継続するUIならチャット、処理の分岐や外部API連携が多いならワークフローが起点になります。
詳細な実装とRAG構築の勘所は、別セクションおよび関連ガイドも参照してください(参考: Features and Specifications | Dify)(参考: API関連Issue)(参考: Workflows API)(参考: External Knowledge API)。
RAGの作り方は、実装パターンを網羅したこちらも役立ちます。RAG(Retrieval-Augmented Generation)構築のベストプラクティス
OpenAI API等との役割分担:いつDifyを挟むべきか
結論として、モデルの切替自由度、GUIでのプロンプト/RAG/ワークフロー調整、ログとフィードバックの一元管理が必要ならDifyを挟むべきです。
一方で、極めてシンプルな単発生成やレイテンシ限界までの最適化、課金制御を自前でやり切るならOpenAI等を直叩きする方が軽量です。
比較の観点を次の表に整理します。
| 観点 | Dify | OpenAI API/Assistants | LangChain(自前実装) |
|---|---|---|---|
| 抽象化レイヤ | AI BaaS(GUI+API) | LLM/ツール実行API | コードライブラリ |
| モデル自由度 | ベンダー中立で切替容易 | 基本はOpenAI系 | 実装次第で自由 |
| 運用機能(LLMOps) | ログ/分析/FB/権限が標準 | 部分的に提供 | 自前で実装・統合 |
| 会話の状態管理 | conversation_idでサーバー側管理 | 基本ステートレス実装が多い | 自前で設計 |
| 導入スピード | 最速(PoC→本番移行が容易) | 速いが運用設計は別 | 要エンジニアリング |
| レイテンシ/コスト微調整 | 抽象化のぶんオーバーヘッド | 最小限 | 最適化自由度が最大 |
意思決定の基準は、短期に価値検証しつつ将来のモデル変更や運用を見据えるならDify、要件が限定的で自前運用が合理的なら直APIです。
導入規模が上がると運用機能の差が効くため、エンタープライズではDifyの評価が定石です(参考: Dify Enterprise)(参考: Plans & Pricing)。
OpenAI直利用の実装ハウツーは、こちらも参考になります。OpenAI APIの使い方をPythonで完全解説
Dify APIの認証と基本リクエスト:まずは1エージェントを動かす
当セクションでは、Dify APIの認証方法と最小リクエスト設計を解説し、1つのエージェントを確実に動かすための初期設定を示します。
なぜなら、Difyは「アプリ単位のAPIキー」「userパラメータ」「conversation_id」による状態管理という独自の前提があり、最初にここを正しく押さえると以降の開発が滑らかになるからです。
- APIキーの種類と取得手順(アプリ単位のキー設計)
- 認証ヘッダーと共通パラメータ設計
- ステートフルな会話管理:conversation_idの考え方
APIキーの種類と取得手順(アプリ単位のキー設計)
結論は、Difyでは「アプリ(エージェント)ごと」にAPIキーを発行し、漏洩時の爆発半径を最小化することが基本戦略です。
この設計により、人事ボットや営業アシスタントなどアプリ単位でアクセス権限と利用状況を分離でき、監査や停止対応もスコープ限定で実施できます。
取得手順は次のとおりです。
- Dify Studioで新規アプリ(チャットまたはワークフロー)を作成する。
- 右上の「公開(Publish)」を有効化し、外部呼び出しを許可する。
- アプリの「API Keys」パネルでキーを生成し、環境変数に安全に保管する。
- ステージング・本番でキーを分離し、ローテーション手順を運用Runbookに明記する。
公開設定をオンにしないとキーが表示されない場合があるため、最初に確認してから発行するのが安全です。
UIは小刻みにアップデートされるため、古い解説と画面差異がある場合は文言や配置を読み替えつつ操作すると混乱を避けられます。

- (参考: Plans & Pricing – Dify)
- (参考: Features and Specifications | Dify)
- (参考: How to Get Dify API Key – Bytebio)
認証ヘッダーと共通パラメータ設計
最小の共通セットは「Authorization: Bearer {API_KEY}」と「user(エンドユーザーID)」で、これを確実に入れることが第一歩です。
理由は、Difyが標準的なBearerトークン認証を採用し、userによってユーザー別の使用量追跡・レート制御・履歴紐づけを行うからです(参考: Features and Specifications | Dify、参考: API-related question · Issue #19825)。
最小のcurl例は次のとおりです。
curl -X POST https://api.dify.ai/v1/chat-messages \
-H "Authorization: Bearer $DIFY_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"query": "休暇規定を教えて",
"inputs": {},
"response_mode": "blocking",
"user": "emp_12345"
}'JavaScript(fetch)の例です。
await fetch("https://api.dify.ai/v1/chat-messages", {
method: "POST",
headers: {
"Authorization": `Bearer ${process.env.DIFY_API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify({
query: "就業規則の目次を要約して",
inputs: {},
response_mode: "blocking",
user: "webuser_abc"
})
});Python(requests)の例です。
import os, requests
resp = requests.post(
"https://api.dify.ai/v1/chat-messages",
headers={
"Authorization": f"Bearer {os.environ['DIFY_API_KEY']}",
"Content-Type": "application/json",
},
json={
"query": "有給の取得ルールは?",
"inputs": {},
"response_mode": "blocking",
"user": "uid-789"
},
timeout=30,
)
print(resp.json())APIキーはフロントに置かずバックエンド経由でルーティングし、環境変数やSecrets Managerで秘匿してローテーション可能にするのが実運用の定石です。

userは匿名ID、メールのハッシュ、社内ユーザーIDのトークン化など衝突しない一意文字列を採用し、個人情報は最小化して扱うと安全です(設計の迷いどころは【図解】Difyの変数を完全理解が参考になります)。
- (参考: Features and Specifications | Dify)
- (参考: API-related question · Issue #19825)
- (参考: Plans & Pricing – Dify)
ステートフルな会話管理:conversation_idの考え方
結論として、conversation_idを正しく保存・再利用するだけで、Difyのステートフル会話管理はほぼ完結します。
理由は、Difyがサーバー側で履歴を保持するため、毎回全履歴を送らずともIDで文脈を引き継げ、帯域やクライアント実装の負担が減るからです(参考: Issue #19843、参考: Features and Specifications | Dify)。
実装は初回リクエストでconversation_idを空にして開始し、レスポンスで受け取ったIDをユーザー単位でDBやセッションに保存し、次回以降の呼び出しに同IDを渡すだけです。
筆者もOpenAIのChat Completionsを直接叩いていた頃は履歴JSONが肥大化しがちでしたが、DifyではIDを握るだけで長文履歴の送信が不要になり運用が軽くなりました。
フロントではlocalStorageやセッションに暫定保存し、バックエンドでユーザーIDと会話IDを正規化してDifyに中継するイメージが現実的です。

IDの寿命・パージ方針・端末切替時の引き継ぎを運用設計に含めると、監査やユーザー体験の一貫性が保てます。
- (参考: Can I create a simple chat agent through an API? · Issue #19843)
- (参考: Features and Specifications | Dify)
チャットボット・エージェントを叩く:/chat-messages の実践
当セクションでは、Difyの対話エンドポイント「/v1/chat-messages」を使ってチャットボット/エージェントを呼び出す実装と運用の勘所を解説します。
なぜなら、このエンドポイントの設計を正しく理解すると、UX、スケール、コスト、ログ管理が一気通貫で最適化できるからです。
- /chat-messagesエンドポイントの基本構造
- ストリーミングレスポンスの扱い(UXと実装ポイント)
- 自社Webサイトにチャットボットを埋め込むAPI連携パターン
/chat-messagesエンドポイントの基本構造
結論は「queryはユーザー発話、inputsはシナリオのパラメータ」であり、response_modeとconversation_idの使い分けがUXと状態管理を決めるということです。
Difyは会話状態をサーバー側で保持するステートフルAPIで、conversation_idを渡すだけで継続会話が成立します。
下図のように、フロントはユーザーの一言をqueryに、アプリ固有の条件やテンプレ変数をinputsに分離して渡します。

具体的なPOST例は次のとおりで、blockingはまとめて返却、streamingはチャンクで返ります。
POST https://api.dify.ai/v1/chat-messages
Authorization: Bearer <YOUR_API_KEY>
Content-Type: application/json
{
"query": "休暇規定を教えて",
"inputs": { "user_name": "佐藤", "department": "人事" },
"response_mode": "streaming",
"conversation_id": null,
"user": "emp_12345"
}主なパラメータは下表のとおりで、OpenAIのように毎回フル履歴を送る必要がない点が実装と帯域の負担を大きく減らします。
| パラメータ | 必須 | 型 | 役割/メモ |
|---|---|---|---|
| query | 必須 | string | ユーザーの発話テキスト |
| inputs | 任意 | object | プロンプトの動的変数やシナリオ条件 |
| response_mode | 必須 | string | blocking または streaming(SSE) |
| conversation_id | 任意 | string | 既存会話の継続ID(未指定で新規) |
| user | 必須 | string | エンドユーザーID(課金・レート制御・ログに利用) |
- (参考: langgenius/dify-docs – GitHub)
- (参考: API Integration – Dify 101 Tutorial)
- (参考: API API-related question · Issue #19825)
設計の詳細や変数の扱いは、図解で理解しやすいこちらも参照してください(【図解】Difyの変数を完全理解)。
ストリーミングレスポンスの扱い(UXと実装ポイント)
チャットらしい“タイピング表示”を実現するなら、response_mode=streaming(SSE)を基本に選ぶべきです。
理由は、SSEが生成中のトークンを即時に受け取れるため、体感レイテンシが大幅に下がりユーザー満足度が向上するからです。
React/Next.jsでは、フロントでEventSourceを使うと最小コードでストリームを描画できます。
// React (Client) 例
useEffect(() => {
const es = new EventSource('/api/chat/stream?q=' + encodeURIComponent(prompt));
es.onmessage = (e) => {
const chunk = e.data; // Difyからのチャンク文字列
setText((prev) => prev + chunk);
};
es.onerror = () => es.close();
return () => es.close();
}, [prompt]);APIキーを守るために、Node.jsのAPI RouteでDifyのSSEをプロキシし、そのままフロントへ転送します。
// Node.js Express/Next.js API Route 例
export default async function handler(req, res) {
res.writeHead(200, {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
Connection: 'keep-alive'
});
const r = await fetch('https://api.dify.ai/v1/chat-messages', {
method: 'POST',
headers: {
'Authorization': `Bearer ${process.env.DIFY_API_KEY}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({ query: req.query.q, response_mode: 'streaming', user: 'u1' })
});
for await (const chunk of r.body) res.write(chunk);
res.end();
}切断や再接続時は最後のペイロードを保持し、EventSourceの再接続で差分描画するだけでも実用に耐えます。
まとめると、会話UIの満足度を優先するならSSEストリーミングを第一選択にしましょう。
- (参考: Can I create a simple chat agent through an API? · Issue #19843)
- (参考: API Integration – Dify 101 Tutorial)
自社Webサイトにチャットボットを埋め込むAPI連携パターン
おすすめ構成は「Next.jsの自前UI+Node API Route+Dify /chat-messages」で、鍵とレート制御を自社側で握りつつ自由なUIを実現します。
理由は、APIキー露出を避けられ、監査ログやユーザー識別(user)を自社基盤に整合させやすいからです。
シーケンスは「フロントが入力送信→自社バックエンドがDifyへ転送→SSEをそのままフロントへ反映」という素直な流れです。

実装は次のAPI Routeスケルトンをベースに、認証と会話IDの引き回しを加えるだけで完成します。
// /pages/api/chat.ts (Next.js)
export default async function handler(req, res) {
const { q, cid, uid } = req.query;
const body = { query: q, response_mode: 'streaming', conversation_id: cid || null, user: uid || 'guest' };
const r = await fetch('https://api.dify.ai/v1/chat-messages', {
method: 'POST',
headers: { 'Authorization': `Bearer ${process.env.DIFY_API_KEY}`, 'Content-Type': 'application/json' },
body: JSON.stringify(body)
});
res.setHeader('Content-Type', 'text/event-stream');
for await (const chunk of r.body) res.write(chunk);
res.end();
}活用例は次のとおりです。
- CS/FAQボット(RAG連携で最新のマニュアルを参照)
- 社内ポータル相談窓口(人事・総務・ITヘルプの横断窓口)
- 営業支援チャット(CRMの案件文脈をinputsに注入)
最小の変更で既存のOpenAIベース構成をDifyに差し替えられるため、PoCから本番への移行もスムーズです。
- (参考: langgenius/dify-docs – GitHub)
- (参考: Plans & Pricing – Dify)
設計をさらに発展させるなら、ビジュアル分岐やHTTPコールを含むワークフローアプリ化も検討しましょう(【2025年版】Dify Workflow完全ガイド)。
社外公開のROI設計にはこちらも併読が便利です(AIチャットボットの費用対効果と導入プラン)。
スキル学習を加速したい場合は実務直結のオンライン講座が近道です(DMM 生成AI CAMP)。
ワークフロー実行:/workflows/run でエージェンティックな処理を呼び出す
当セクションでは、Difyのワークフロー実行エンドポイント「POST /workflows/run」の使いどころ、入力設計、長時間実行時の設計指針を解説します。
なぜなら、チャットAPIとワークフローAPIの役割を取り違えると、UXや保守性、コストに大きな影響が出るためです。
- Workflow APIの役割とチャットAPIとの違い
- /workflows/run のリクエスト設計とinputsのマッピング
- 長時間実行ワークフローへの対応:タイムアウトと非同期化のコツ
Workflow APIの役割とチャットAPIとの違い
結論として、業務フローや外部API連携を含む「エージェンティック」な処理は/workflows/run、シンプルな対話は/chat-messagesを使い分けるのが最適です。
その理由は、ワークフローAPIがLLMノード、HTTPリクエスト、イテレーションなど複数ノードからなるグラフを一括実行する「オーケストレーター」であり、チャットAPIは会話文脈を維持した対話に最適化されているからです。
例えば「経費精算エージェント」では、社内規程のRAG検索、明細のループ検査、ERPへの書き込み、承認分岐と要約生成までをひと綴りで動かすため、ワークフローAPIが適任です。
下図のイメージのように、/workflows/runは内部でノードグラフを一気に実行し、分岐・再試行・データ受け渡しを管理します。

一方でFAQ対応や軽量Q&Aのように、文脈付きのやり取りが中心なら/chat-messages、単発の文章生成なら/completion-messagesが速くて簡潔です。
したがって、要件が「対話」か「業務フロー」かでエンドポイントを切り分け、/workflows/runはエージェント的な自動化の中核として採用します。
参考リンク:
- (参考: About workflows API Issues #9513 – langgenius/dify)
- (出典: Features and Specifications | Dify)
- (参考: langgenius/dify-docs)
関連記事の詳説は【2025年版】Dify Workflow完全ガイドも参考になります。
/workflows/run のリクエスト設計とinputsのマッピング
結論は、Startノードで宣言した入力パラメータと、APIリクエストのinputsオブジェクトのキーを1対1で揃えることです。
理由は、Difyがinputs内のキー名でバインドを行い、以降のノードへ安全にデータフローを渡す設計になっているためで、sys.*のシステム変数は内部で自動処理されます。
例えばStartノードにarticle_url、target_language、toneを定義した場合、次のようにJSONを渡します。
POST https://api.dify.ai/v1/workflows/run
Authorization: Bearer <API_KEY>
Content-Type: application/json
{
"inputs": {
"article_url": "https://example.com/post/123",
"target_language": "ja",
"tone": "formal"
},
"response_mode": "blocking",
"user": "employee-1234"
}また最終ノードで出力名summaryを定義しておけば、レスポンスのoutputs.summaryから最終結果を取得できます。
下図は「Startノードの入力パラメータ」とAPIのinputsキーが1対1に対応する様子を示したものです。

変数名はスネークケースなど一貫性を保ち、型(文字列・配列・数値)をワークフロー側と揃えると検証と保守が安定します。
したがって、「Startノード=API契約」だと捉えてスキーマを固定し、予測可能なI/Oを設計するのが実践的です。
参考リンク:
- (参考: About workflows API Issues #9513 – langgenius/dify)
- (出典: Workflow Major Update: Iteration, Parameter Extractor and Publish Workflow as a Tool – Dify)
- 関連: 【図解】Difyの変数を完全理解
長時間実行ワークフローへの対応:タイムアウトと非同期化のコツ
ポイントは、数十秒〜数分の処理は非同期前提で設計し、タイムアウト回避と再実行性を確保することです。
理由は、blockingレスポンスだけに依存するとHTTPやリバースプロキシの制限にかかりやすく、UXや信頼性が損なわれるためで、SSEストリーミングも万能ではありません。
アプローチ1は「バックエンドとフロント双方のタイムアウト延長+Keep-Alive」で、短〜中程度の処理に向きますが、ネットワーク環境に左右されます。
アプローチ2は「非同期+ステータス取得APIやWebhook」で、実行直後にrun_idを返し、ポーリングやWebhookで最終結果を受け取り、キュー処理や自動化ツールと連携すると運用が安定します。
アプローチ3は「バッチ処理」で、呼び出しをキューに積み、別プロセスで順次実行してポーリングや通知で完了を検知する構成です。
総じて、「適切なタイムアウト設定+非同期ポーリング/Webhookの組み合わせ」で長時間実行を堅牢化するのが現実解です。
下図は非同期化の設計スケッチです。

参考リンク:
- (参考: How to make an API call for a long-running workflow? · Discussion #25792)
- (参考: dify/api/core/app/apps/base_app_runner.py)
- (出典: Features and Specifications | Dify)
シングルターン生成とユーティリティ用途:/completion-messages の使いどころ
当セクションでは、/completion-messages の役割と適したユースケース、チャットとの違い、そして実運用での活用パターンを説明します。
なぜなら、エンドポイント選定はレイテンシ、コスト、状態管理の複雑さに直結し、プロダクション品質と運用性を大きく左右するからです。
- /completion-messagesでできることとチャットとの違い
- バックエンドバッチ処理・マイクロサービスとしての活用例
/completion-messagesでできることとチャットとの違い
/completion-messages は一問一答のテキスト生成に特化し、一度の入力から確定した出力を素早く返す用途に最適です。
Dify側に会話履歴を保持しないため、サーバーセッションや conversation_id の管理が不要になります。
応答は blocking と streaming の両方に対応し、プロンプトで定義した動的変数は inputs に渡して完結します。
代表的な用途は次のとおりです。
- CRM連携の「顧客メモ→お礼・お詫びメールの下書き」自動生成
- CMSの「記事要約」ボタンでのメタディスクリプションや冒頭リード生成
- 問い合わせフォームの自由記述を社内語に正規化するテキスト整形
- 多言語翻訳やスタイル変換(敬語化、カジュアル化、文体統一)
- 件名A/Bテスト用の短文コピーやコードスニペットの単発生成
複数ターンの対話や長期記憶が必要なときだけ /chat-messages を選び、それ以外は本エンドポイントを標準にするのが実装効率とコストの観点で合理的です(参考: Features and Specifications | Dify)。
バックエンドバッチ処理・マイクロサービスとしての活用例
/completion-messages は定期バッチや軽量マイクロサービスのバックエンドから呼び出すとプロンプト運用の一元化と変更耐性の高さで効果が大きいです。
プロンプトやモデル選択をDifyに置くことで、コードを触らずに精度改善やモデル切り替えを行えます。
ログやコストの可観測性もDify側でまとまり、失敗時の再試行やレート制御をクライアントに持ち込まずに済みます。
定期バッチの例は次のとおりです。
- 前日の問い合わせログを部署別に要約し、朝に配信するレポート生成
- 営業日報の箇条書きを「読みやすいレポート文」へ整形
- SLA逸脱アラートの通知本文を自動ドラフト
マイクロサービスとしては次のような小粒APIに向きます。
- テキスト整形API(句読点の統一、社内用語の置換、禁止語チェック)
- CRMトリガーで呼ぶ「案件フェーズ別メール雛形」生成
- 個人情報の擬似化・マスキング用の説明文生成
既存のPythonスクリプトのOpenAI直叩きをDifyに置き換えるイメージは次のコードと図が参考になります。
import os, requests
API_KEY = os.getenv("DIFY_API_KEY")
URL = "https://api.dify.ai/v1/completion-messages"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"inputs": {
"raw_notes": "顧客A: 納期遅延に不満。来週の代替案提案を希望。",
"tone": "polite"
},
"response_mode": "blocking",
"user": "cron-reporter"
}
resp = requests.post(URL, headers=headers, json=payload, timeout=60)
print(resp.json())
より複雑な自動化が必要ならワークフロー併用も検討し、外部システム連携はDify Workflow完全ガイドや実装の比較はOpenAI APIのPython解説が手がかりになります(参考: Features and Specifications | Dify)。
ナレッジベースとRAG:データセットAPI・外部ナレッジAPIの実務
当セクションでは、DifyのナレッジベースとRAGを「標準機能」と「API」双方から設計・運用する実務手順を解説します。
理由は、RAGの精度・再現性・コストはデータ取り込みと検証、そして既存検索基盤との接続方式の選び方で大きく変わるからです。
- DifyのナレッジベースとRAGパイプラインの仕組み
- APIでデータセットを管理する:アップロードとヒットテスト
- 既存の検索基盤を活かす:External Knowledge APIの使いどころ
DifyのナレッジベースとRAGパイプラインの仕組み
結論として、Difyのナレッジベースは「ドキュメントを置くだけでRAGに必要なETL・ベクトル化・検索・再ランクを統合運用できる」仕組みです。
PDFやMarkdown、HTMLをアップロードすると、自動でテキスト抽出→チャンク分割→埋め込み生成→ベクトル格納が走り、アプリ側では「RAG対応エージェント」から参照できます。
たとえば人事規程PDFを入れておけば、チャットやワークフローから社内規程を引用付きで回答でき、詳しくは【2025年版】Difyの「ナレッジ」完全ガイドや【ノーコードでOK】Dify×RAG完全ガイドが参考になります。

またモデル非依存の設計により、RetrieverやReranker、LLMを差し替えながら最適な構成を比較検証できます。
結果として、知識は「学習」ではなく「参照」で活用され、精度と変更容易性を両立できます。(参考: Features and Specifications | Dify)(参考: Dify’s Feature Step by Step: Knowledge Base – YouTube)
APIでデータセットを管理する:アップロードとヒットテスト
結論は、データセットAPIで「アップロード→ETL→埋め込み生成→ヒットテスト」までを自動化し、RAGの再現可能な検証ループを作ることです。
理由は、API経由で取り込みと検証を一貫操作できると、チャンクサイズやオーバーラップ、再ランカーの有無といったパラメータの因果が追いやすく、精度チューニングが短時間で進むためです。
まず、特定データセットへファイルをアップロードします。
curl -X POST 'https://api.dify.ai/v1/datasets/{DATASET_ID}/documents' \
-H 'Authorization: Bearer {API_KEY}' \
-F 'file=@./hr-policy.pdf' \
-F 'indexing_technique=high_quality' \
-F 'process_rule[chunk_size]=800' \
-F 'process_rule[chunk_overlap]=200'次に、Hit Testingで「このクエリに対して何が引っかかったか」を確認します。
curl -X POST 'https://api.dify.ai/console/api/datasets/{DATASET_ID}/hit-testing' \
-H 'Authorization: Bearer {API_KEY}' \
-H 'Content-Type: application/json' \
-d '{
"query": "有給の繰越上限は?",
"top_k": 5,
"rerank": true
}'{
"results": [
{"document_id": "doc_123", "score": 0.82, "content": "翌年度への繰越上限は20日…", "metadata": {"page": 5, "source": "hr-policy.pdf"}},
{"document_id": "doc_456", "score": 0.76, "content": "付与と繰越の関係は…", "metadata": {"page": 6}}
],
"embedding_model": "text-embedding-3-large",
"reranker": "bge-reranker-large"
}
この検証結果をもとに、チャンク規則や再ランカー有無を見直してから、ワークフローやエージェントに反映すると改善が速く、作り方はRAG構築のベストプラクティスやDify Workflow完全ガイドが参考になります。(参考: Dify.AI’s New Dataset Feature Enhancements)(参考: Request for adding an API to do retrieval from knowledge base)
既存の検索基盤を活かす:External Knowledge APIの使いどころ
結論として、社内にElasticsearchや独自ベクトルDBがあるなら、External Knowledge APIで「Difyから社内検索APIを呼ぶ」構成が最小コストで安全です。
理由は、データをDifyに二重保存せずガバナンスとデータレジデンシ要件を満たせ、VPC内の一次ストレージに留めたままRAGの利便性を享受できるからです。
実装は、Dify仕様に沿ったブリッジAPIを用意し、ユーザー質問を受けて外部検索基盤にクエリし、関連テキストとメタデータを返すだけのシンプルな疎結合です。

エンタープライズでは「ゼロコピー」「最小権限」「監査ログ集中」を原則に、レスポンススキーマの安定性とスロットリングを明示し、障害時のフォールバック戦略も設けると安全です。
結果として、移行コストを抑えつつ検索品質の資産を活かせ、体系的に学ぶならDMM 生成AI CAMPのような実践カリキュラムも有効です。(参考: External Knowledge API – Dify)(参考: もばらぶエンジニアブログ)
運用・LLMOpsの視点:ログ、フィードバック、エラー処理とセキュリティ
当セクションでは、運用・LLMOpsの観点からログとフィードバック、エラーハンドリング、セキュリティとコンプライアンス対応の実務ポイントを解説します。
本番運用でAI品質とSLAを両立するには、観測可能性に基づく継続改善、堅牢な失敗設計、鍵管理と認証の原則が不可欠だからです。
- ログとフィードバックAPIで継続改善する
- 典型的なエラーとハンドリングパターン
- セキュリティ・コンプライアンス:フロントから直叩きしない理由とエンタープライズ対応
ログとフィードバックAPIで継続改善する
結論として、Difyのログ可視化とフィードバックAPIを組み合わせて“計測→学習→改善”のループを回すことが、品質向上の最短ルートです。
Difyのダッシュボードではメッセージログ、モデル別トークン使用量、ユーザーごとの利用状況を横断して確認でき、どのプロンプトやナレッジが成果に寄与しているかを定量で把握できます(参考: Features and Specifications | Dify)。
アプリ側からは /messages/:message_id/feedbacks へ「Good/Bad」と任意コメントを送信でき、FAQボットの回答にLike/Dislikeと自由記述を載せる設計にするだけで改善材料が一気に蓄積します。
POST https://api.dify.ai/v1/messages/{message_id}/feedbacks
Authorization: Bearer <API_KEY>
Content-Type: application/json
{
"rating": "good", // or "bad"
"comment": "参照資料のURLが古いです。最新規程に更新してください"
}このデータはダッシュボードのログと紐づくため、Badが多いトピックのプロンプトやナレッジを一括見直しでき、RAGの当たりを検証する際はヒットテストと併用すると効果的です(参考: External Knowledge API、内部解説: 【2025年版】Difyの「ナレッジ」完全ガイド)。
最終的に、ログとフィードバックをスプリントのKPIに落とし込み、Bad→改善→再計測のサイクルを週次で回す運用が現場では最も再現性が高いです。


参考:
- Features and Specifications | Dify
- langgenius/dify-docs – GitHub
- 関連解説: 【ノーコードでOK】Dify×RAG完全ガイド / 【図解】Difyの変数を完全理解
典型的なエラーとハンドリングパターン
要点は「429と一部の5xxはリトライ、400/401は即時修正、ユーザーには行動可能な一文だけ見せる」です。
Difyは標準HTTPステータスを返し、原因はパラメータ不足や無効キー、レート制限超過、プロバイダー側の一時障害などに分類できます(参考: Features and Specifications | Dify)。
特にレート制限はプランに依存するため、外部公開の本番はTeamプランで一般APIのレート制限撤廃を前提に設計すると事故が減ります(参考: Plans & Pricing – Dify)。
| HTTP | 主な原因 | クライアント対処 | ユーザー表示 | 監視/アラート |
|---|---|---|---|---|
| 400 | 必須フィールド欠落・JSON不備 | 入力バリデーション強化、再送不要 | 入力内容を確認してください | アプリケーションエラーカウント |
| 401 | APIキー無効/期限切れ | キー更新、サーバー側で再認証 | 一時的な接続エラーです | 認証失敗率の閾値監視 |
| 429 | レート制限超過 | 指数バックオフ+ジッターでリトライ | 混雑のため処理中です | 429発生率・キュー長 |
| 5xx | 一時的障害/タイムアウト | 冪等リトライ、SSE再接続 | 復旧までお待ちください | 外形監視・SLAアラート |
// 擬似コード: 429/5xx向け指数バックオフ+ジッター
async function callWithRetry(fn, max=4){
for (let i=0;i<=max;i++){
const r = await fn();
if (r.ok) return r;
if (![429,500,502,503,504].includes(r.status)) throw r;
const base = 2 ** i * 300; // ms
const jitter = Math.random() * 200;
await new Promise(res => setTimeout(res, base + jitter));
}
throw new Error('Max retries exceeded');
}PMの経験上、ユーザーに内部識別子やスタックトレースを出すと混乱を招くため、画面は短い説明+再試行案内に留め、詳細はログ相関IDでSREが追跡できる設計がベストです。
最後に、リトライ率・失敗率・P95レイテンシをダッシュボード化し、閾値でPagerDutyやOpsgenieに通知すると復旧時間が短縮します(内部解説: AIハルシネーション対策の全手法)。
参考:
セキュリティ・コンプライアンス:フロントから直叩きしない理由とエンタープライズ対応
原則は明快で、APIキーは必ずサーバーサイドに置き、React/Vueなどのフロントコードから直接Difyを叩かないことです。
フロント埋め込みは鍵漏えいの致命リスクがあり、アプリレベルでスコープされたDifyキーでも被害範囲は限定されるものの、悪用は防げないためバックエンドを必須とします(参考: Features and Specifications | Dify)。
エンタープライズ対応として、DifyはSOC 2 Type II、ISO 27001:2022、GDPR準拠を公表し、EnterpriseではVPC内デプロイやSSO(SAML/OIDC)連携が可能です(出典: Dify Trust Center、Get Compliance Report | Dify、AWS Marketplace: Dify Enterprise)。
セキュリティレビュー時に送るとよい情報は次のとおりです。
- データフロー図(PIIの取り扱い、暗号化ポイント、保存先)
- サブプロセッサ一覧とデータレジデンシー
- 鍵管理方針(KMS/ローテーション/権限分離)
- アクセス制御(SSO/MFA/ロール設計)
- 監査ログと保持期間、削除ポリシー
- 脆弱性対応SLAとペネトレーションテスト結果の要約
詳細は当サイトの解説も参照してください(内部解説: 【最新2025年版】Difyのセキュリティ徹底解説 / 生成AIのセキュリティ完全解説 / プロンプトインジェクション対策の決定版ガイド)。
社内のリスキリングや設計レビュー体制を強化したい場合は、実務カリキュラムが整った学習プログラムの活用も有効です(例: DMM 生成AI CAMP)。
参考:
料金・コスト設計:プラン選択とTCOの考え方
当セクションでは、Difyの料金プランの違いとAPI制限、BYOKによる課金構造、そして自前構築とのTCO比較の考え方を解説します。
理由は、Difyはサブスク料金とモデル利用料が分離しており、プラン選択や設計を誤ると本番で詰まるリスクが高いからです。
- 2025年時点の主な料金プランとAPI制限の違い
- BYOKモデル課金と「見えないコスト」の把握
- 「自前構築 vs Dify」のコスト比較と判断の目安
2025年時点の主な料金プランとAPI制限の違い
結論として、本番運用の分岐点はTeamプランで、ここからAPIレート制限が実質撤廃されます。
理由は、Sandbox/Professionalはテスト〜小規模向けの制限が多く、対外提供や高頻度利用に耐えにくいためです。
具体的には、メンバー数、アプリ上限、月間メッセージ、ベクトルストレージ、レート制限で差が明確に出ます。
ナレッジ検索のレートもProfessionalの約100/分からTeamでは1,000/分へと拡張され、RAGのスループットが改善します。
より丁寧な比較や運用シナリオ別の選び方は、詳説記事「Difyの料金プランを徹底比較」や「無料でできること・制限」も参照してください。
以下は2025年11月時点の公式情報を要約した比較表で、数値や仕様は将来変更される可能性があります(出典: Plans & Pricing – Dify)。
| プラン | 価格 | チームメンバー | アプリ上限 | メッセージ | ベクトルストレージ | APIレート制限 | ログ履歴 | セキュリティ |
|---|---|---|---|---|---|---|---|---|
| Sandbox (Free) | 無料 | 1名 | 10個 | 200回(合計) | 5MB | 制限あり | 限定的 | 標準 |
| Professional | $59/月 | 3名 | 50個 | 5,000回/月 | 200MB | 制限あり(例: ナレッジ約100/分) | 無制限 | 標準 |
| Team | $159/月 | 50名 | 200個 | 10,000回/月 | 20GB | APIレート制限なし(ナレッジ約1,000/分) | 無制限 | 標準 |
| Enterprise | カスタム | 無制限 | 無制限 | カスタム | 無制限/カスタム | レート制限なし | 無制限 | SSO/監査ログ |
BYOKモデル課金と「見えないコスト」の把握
ポイントは、DifyはBYOK方式のためサブスクとは別に各モデルプロバイダへのトークン課金が必ず発生することです。
この構造上、Difyの月額だけ見ても総額は読めず、モデル単価と利用量の見積もりがTCOのカギになります(参考: Plans & Pricing – Dify)。
例として、1,000ユーザーが1人あたり1日5メッセージ、月30日なら月間15万ラウンドで、1往復あたり合計1,000トークン想定なら月1.5億トークンです。
モデルの平均単価を$0.2〜$5/100万トークンのレンジで見積もると、LLM料金は約$30〜$750/月と幅が出るため、事前のプロンプト最適化とレスポンス長管理が効きます。
プロンプトの型化はコスト最適化に直結するため、実務ノウハウを短時間で学ぶ資料として『生成AI 最速仕事術』の活用も有効です。
さらに、ツール開発工数、ログ監視・改善の人的コスト、外部RAGストレージ費用などの「見えないコスト」を合算して判断することが大切です。

「自前構築 vs Dify」のコスト比較と判断の目安
結論は、中小〜中堅の規模ではDify Team($159/月)+モデル料金の方が総コストと市場投入速度で有利になりやすいです。
理由は、LangChain+ベクトルDB+監視基盤の自前統合は初期構築と継続運用の人件費が支配的で、スケールしない限り回収が難しいためです。
一例として、最小構成の自前運用でもクラウド/DB/監視で$300〜$1,000/月に加え、保守0.3〜0.5人月の人件費が恒常的に発生します。
一方でDifyはワークフローやRAG、可観測性が統合され、PoC→パイロット→本番の移行が早く、私が担当した資格試験システム規模でも「Difyなら数週間早かった」と感じたポイントがUX改善とログ起点の反復でした。
ただし、数百万ユーザー級の超大規模や厳格なデータレジデンシー要件では、自前スタックかセルフホストのDify Enterpriseも選択肢になります。
詳細は以下を参照し、オンプレやVPC展開の是非は「ローカル導入ガイド」や「Dify×AWS徹底解説」の手順と合わせて検討してください。
| 観点 | 自前最小構成(例) | Dify Team(例) |
|---|---|---|
| 月額インフラ | $300〜$1,000 | $159(サブスク) |
| 人件費(運用) | 0.3〜0.5人月 | 0.05〜0.2人月 |
| 開発スピード | 要件次第で数週〜数ヶ月 | 数日〜数週 |
| スケール/制御 | 柔軟だが重運用 | Teamで十分/超大規模はEnterprise |
ユースケース別:Dify APIをどう組み込むか実装イメージ
当セクションでは、代表的な3つのユースケースに沿ってDify APIの実装イメージを解説します。
なぜなら、要件ごとに「どのエンドポイントをどこから呼ぶか」と「UI/セキュリティ/コスト設計」を早期に描けると、PoCから本番への移行が滑らかになるからです。
- ユースケース1:自社Webサイト向けFAQチャットボット
- ユースケース2:バックエンドからのバッチワークフロー起動
- ユースケース3:社内ナレッジ検索エージェント(Slack/Teams連携)
ユースケース1:自社Webサイト向けFAQチャットボット
結論は、Next.jsのBFF経由で /chat-messages をSSE呼び出しし、DifyのナレッジでRAG回答を返す構成が最短で安全です。
理由は、フロントにAPIキーを置かずに済み、会話状態はconversation_idでDify側が保持するため、実装と帯域の両面で効率的だからです。
具体的には「Difyでアプリ作成とナレッジ登録→APIキー発行→自社BFFから /v1/chat-messages を呼び出し→フロントでストリーミング表示」という順序で組み込みます。
ウィジェット埋め込みは最短導入に便利ですが、ブランド統一や権限連携、観測性の要件が強い場合はAPI実装の方が拡張しやすいです。
エンドポイント仕様とSSEの扱いは公式ドキュメントに準拠します。

- (1) Difyでアプリ作成しPDF/URL等を「ナレッジ」に投入してRAGを有効化
- (2) アプリ単位のAPIキーを発行し、サーバー環境変数で管理
- (3) Next.jsのAPI RouteからAuthorization: Bearerで /v1/chat-messages を呼び出し
- (4) フロントはSSEチャンクを受け取り、入力中のようにストリーム描画
// app/api/chat/route.ts(Next.js 14)
export async function POST(req: Request) {
const { query, conversationId, user } = await req.json();
const difyRes = await fetch('https://api.dify.ai/v1/chat-messages', {
method: 'POST',
headers: {
'Authorization': `Bearer ${process.env.DIFY_API_KEY}`,
'Content-Type': 'application/json',
},
body: JSON.stringify({
query,
response_mode: 'streaming',
user, // エンドユーザー識別子
conversation_id: conversationId || undefined,
})
});
return new Response(difyRes.body, {
headers: { 'Content-Type': 'text/event-stream' }
});
}
RAGの作り込みやデータ投入手順はDify×RAG完全ガイドが参考になります。
APIの形式やSSEストリーミングの詳細は公式リポジトリのドキュメントを参照してください(参考: Dify Docs)。
ユースケース2:バックエンドからのバッチワークフロー起動
結論として、毎朝の集計や要約配信は、自社のCronやスケジューラから /workflows/run を叩き、Difyのワークフローで集計・整形・通知までを一気通貫に回すのが堅実です。
理由は、長めの処理や外部API連携、テンプレート整形をワークフローのノードで可視化・運用でき、失敗時の再実行や改善も容易だからです。
たとえば「売上データ取得→LLMで要約→Slack通知」をワークフローに組み、Cron側はinputsとユーザーIDを渡すだけにします。
HTTPタイムアウトを避けるにはblockingではなくストリーミングや非同期設計、もしくはポーリングを選ぶのが現実的です。
ZapierやMakeなどのiPaaSから同じエンドポイントを呼ぶ方式も有効で、ノーコード運用とエンジニアリング運用を柔軟に切り替えられます。

# run_daily.py(Python)
import os, requests
DIFY_KEY = os.getenv('DIFY_API_KEY')
WF_URL = 'https://api.dify.ai/v1/workflows/run'
inputs = { 'date': 'yesterday', 'channel': '#daily-report' }
res = requests.post(WF_URL,
headers={'Authorization': f'Bearer {DIFY_KEY}', 'Content-Type': 'application/json'},
json={'inputs': inputs, 'response_mode': 'blocking', 'user': 'batch-cron'})
res.raise_for_status()
print(res.json()) # 必要に応じてロギングや失敗通知
# crontab例:毎朝9時に実行
0 9 * * * /usr/bin/python3 /opt/apps/run_daily.py >> /var/log/dify-batch.log 2>&1
ワークフローAPIの仕様や長時間実行時の扱いは公式のアナウンスやIssueを確認してください(参考: About workflows API、長時間ワークフローの扱い)。
ワークフロー設計の基本はDify Workflow完全ガイドが詳しいです。
ユースケース3:社内ナレッジ検索エージェント(Slack/Teams連携)
結論は、Slack/TeamsのSlashコマンドやメンションをトリガーに、自社Botサーバーから /chat-messages を呼び、RAGや外部ナレッジAPIで社内情報を引いたうえで即時回答する構成が実用的です。
理由は、コラボレーションツールが認証とイベントを標準化しており、Difyが検索と生成のオーケストレーションを担うことで、実装量と運用負荷を大幅に減らせるからです。
構成は「Slack/Teams→Botサーバー→Dify /v1/chat-messages→回答」という直列で、必要に応じてExternal Knowledge APIで既存の検索基盤へブリッジします。
データをDifyに複製しない運用が必要な場合は外部ナレッジ連携が有効で、ナレッジ運用の基礎はDifyのナレッジ完全ガイドが参考になります。
セキュリティ観点ではSSOや監査対応の整備が進んでおり、社内展開でも要件を満たしやすいのが利点です(参考: Dify Trust Center、External Knowledge API)。

- Slashコマンドで問い合わせを受け、user識別子を付けてDifyへ転送
- RAGはDifyナレッジか、既存の検索基盤をExternal Knowledge APIでブリッジ
- 回答はチャットにスレッド返信し、必要に応じてフィードバックを記録
- プロンプト安全性はプロンプトインジェクション対策を参考に基準化
この構成は筆者が過去に実装したマーケティング自動化プロジェクトとも近く、スモールスタートから部門横断展開まで段階的にスケールしやすいです。
実装や社内教育を並走させるなら、基礎から業務適用まで体系化された学習サービスの活用も有効です(例: DMM 生成AI CAMP)。
どんな組織・案件でDify APIがフィットするか:導入判断のチェックリスト
当セクションでは、どんな組織・案件でDify APIが最適かを判断するための観点と、導入前に確認すべき実務チェックリストを解説します。
なぜなら、DifyはRAGやエージェントを含む「AIバックエンド(BaaS)」を抽象化する一方で、要件によっては他手段の方が効果的な場合もあるため、冒頭で意思決定の軸を揃える必要があるからです。
- Difyが特に向いているパターン
- 逆にDifyを選ばないほうがよいケース
- 導入前に確認したいチェックリスト
Difyが特に向いているパターン
ノンエンジニアを含めてAIエージェントを素早く試し、RAGや複雑なワークフローを“自前バックエンドなし”で動かしたい組織に、Difyは強く適合します。
DifyはLLMOpsやRAG、ワークフロー、モデル切り替えを統合したBaaSで、API一つで設計から運用までつなげられるため、内製の配管作業を最小化できます(出典: Dify 公式)。
モデル中立性によりGPT系からClaudeやLlamaへの移行も設定変更で柔軟に行え、将来のベンダーロックインを回避しやすい点も実運用で効きます(出典: Dify 公式)。
実例としてVolvoやRicohは、市民開発者を巻き込みつつエージェントやNLPパイプラインを加速し、市場投入までの時間とコストを削減しました(参考: Volvo Case、参考: Ricoh Case Studies)。
エンタープライズではSOC2/ISO27001/GDPRへの準拠やSSO対応などのガバナンス機能が導入障壁を下げ、より安全に本番展開できます(参考: Dify Trust Center)。
結果として、PoCから本番までの学習曲線が穏やかになり、RAGやワークフローを段階的に高度化できるため、スピードとガバナンスの両立を狙う場合に最有力となります(関連記事: Dify Workflow完全ガイド、最新事例に学ぶDify活用術)。
逆にDifyを選ばないほうがよいケース
本当にシンプルなテキスト生成だけで足りる、ミリ秒単位の超低レイテンシが必須、あるいは完全カスタムのLLMパイプラインをコードで細かく制御したいなら、Dify以外の選択肢を検討すべきです。
例えば一問一答の生成だけで十分なら、オーバーヘッドの少ないモデル直叩きの方がコストとレイテンシで有利になりやすいです(関連: OpenAI APIの使い方をPythonで完全解説)。
また、数十ミリ秒単位まで詰めたいリアルタイム要件や、キャッシュ・再試行・ツール呼び出しを低レベルに最適化したい場合は、LangChain+自前基盤のほうが自由度が高いことがあります(関連: LangChain入門)。
Difyは可観測性やステート管理など多くを抽象化する反面、その抽象化レイヤーが極限チューニングには不向きな局面もあります。
現実的には、PoCはDifyで迅速に検証し、要件が固まってから一部ワークロードをコードベースへリファクタリングする“ハイブリッド”が合理的です。
著者は「ツール導入ありき」ではなくビジネス要件から選定する立場であり、要件に合う手段を中立に提示します。
導入前に確認したいチェックリスト
次の5項目をチームで合意してから進めると、導入判断の精度が大きく上がります。
Difyはワークフロー、RAG、API統合を横断するため、要件の曖昧さがそのまま精度やコストのブレに直結します。

データ準備はRAG精度の土台なので、ドキュメントの正規化や権限設計、更新頻度を事前に棚卸ししておきます(関連記事: Difyの「ナレッジ」完全ガイド、RAG構築のベストプラクティス)。
セキュリティとコンプライアンスは調達の主要ゲートであり、SOC2/ISO/GDPRの証跡とSSO要件を事前に確認します(参考: Dify Trust Center)。
想定ユーザー数とトラフィックは料金プラン選定に直結し、特に本番ではTeamプランのレート制限撤廃が分岐点になります(関連記事: Difyの料金プランを徹底比較、出典: Dify Official Pricing)。
このチェックリストを埋めたうえで、最新の料金とドキュメントを確認し、PoC→パイロット→本番のロードマップとKPIを合意してください(関連記事: Difyのセキュリティ徹底解説)。
- どの業務プロセスに適用するか(対象範囲、成功指標、影響部門)
- データ(ナレッジ)の準備状況(形式、鮮度、アクセス権、増分更新)
- セキュリティ/コンプライアンス要件(SOC2/ISO/GDPR、SSO、監査ログ)
- 想定ユーザー数とトラフィック(ピーク時、SSE/バッチの混在、SLA)
- PoC〜本番ロードマップ(マイルストーン、ガバナンス、費用見通し)
社内のAIリテラシー強化が並行課題であれば、実務寄りの学習プログラムの活用も有効です(例: DMM 生成AI CAMP)。
まとめと次の一歩:Dify APIで現場実装を加速する
DifyはLLMのBaaSとして、モデル非依存のオーケストレーション、/chat-messages・/workflows/run・/completion-messagesの要点、RAGとLLMOps、Teamプラン中心のコスト設計までを整理しました。
大切なのは「まず動かす」こと——小さな成功が要件とTCOを具体化し、導入判断の精度を一気に高めます。
まず1エージェントを作り、/chat-messagesか/workflows/runで最小プロトタイプを1週間以内に実装し、想定ユーザー数と負荷からSandbox/Professional/Teamを見極めましょう。Difyのサインアップ・Pricing・APIドキュメントも確認を。
設計力を磨くなら『生成AI 最速仕事術』や『生成AI活用の最前線』が最短ルートです。