
(最終更新日: 2026年07月01日)
社内の規程やマニュアルに答えるAIを作りたいのに、難しい言葉ばかりで一歩目が出ない――そんな悩みはありませんか。
この記事はDifyを使い、コード不要で自社データ対応のチャットボットを1日で試作する道筋を示します。
まずChatGPT単体との違いと、社内資料を根拠に答える仕組みをやさしく整理。
続いて導入形態の選び方、画面に沿った作成手順、PDFやExcelの取り込みのコツを解説。
精度調整と安全な運用、社内FAQやサポートへの活用までを、現場で得た知見と最新検証に基づき具体的に案内します。
RAGとDifyをざっくり理解する:ChatGPT単体との違いから押さえる
当セクションでは、RAGの基本概念とDifyの全体像を、ChatGPT単体との違いを軸に整理して解説します。
理由は、社内ナレッジを扱うチャットボットの品質は“検索してから生成する”設計に大きく依存し、さらに将来的な業務横展開まで見据えると、RAGに強い統合プラットフォーム選びが成功の分岐点になるからです。
- RAGとは何か?なぜ社内マニュアル検索に向いているのか
- Difyとは?RAGだけのツールではなく“AIアプリ開発OS”である
- Dify標準RAGの特徴:ナレッジパイプラインとプラグインエコシステム
RAGとは何か?なぜ社内マニュアル検索に向いているのか
結論、RAGは「関連ドキュメントを検索→その内容を踏まえて生成」という二段構えで、社内マニュアル検索に最適です。
汎用LLMは多くの場合、自社ルールや最新手順を学習していません。
また、セキュアな社内資料に直接アクセスできないため、ChatGPT単体では正確に答えにくいのが実情です。
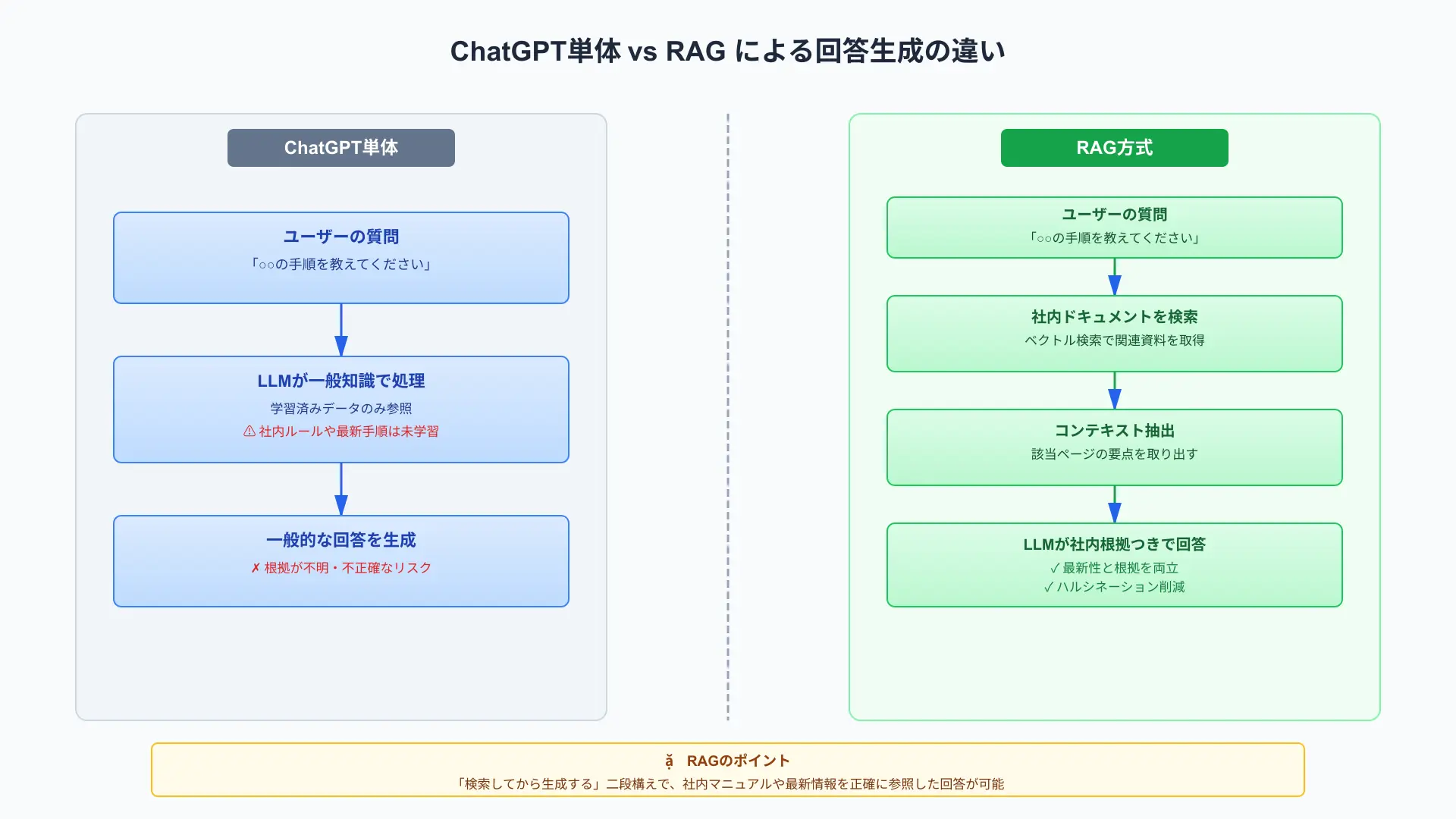
RAGでは質問を受けたら社内ドキュメントを検索し、該当ページの要点を抽出してから回答を生成します。
この流れは最新性と根拠の提示を両立し、問い合わせ対応の属人化やハルシネーションを減らせます。
まずは“検索してから書く”を理解すれば、RAG導入の全体像が掴めます。
実装上の勘所はRAG構築のベストプラクティスで詳しく解説しています。
Difyとは?RAGだけのツールではなく“AIアプリ開発OS”である
DifyはRAG専用ツールではなく、エージェントやワークフロー、LLMOpsまで統合した“AIアプリ開発OS”です。
一つのキャンバスでRAGとエージェントを組み合わせ、業務フロー全体を可視化できるため、チャットボットから申請自動化やレポート生成まで横展開しやすいからです。
中心機能はドラッグ&ドロップのVisual Workflow Builderで、複雑なロジックもノーコードで組み立てられます(参考: Dify)。
さらにモデル中立設計でGPTやClaudeに加えOSSモデルも切り替え運用でき、利用状況やコストを追えるLLMOps機能も備えます(参考: GitHub: langgenius/dify)。
SaaSからセルフホストまで提供され、AWSとAzureのマーケットプレイスにも公式展開があるため、企業のガバナンス要件にも適合しやすいです(参考: AWS Marketplace: Dify Premium、Microsoft Marketplace: Dify Enterprise)。
だから“将来の拡張まで見据えた基盤”としてDifyを選ぶメリットが大きいです。
導入の始め方はDifyの使い方で手順を確認できます。
Dify標準RAGの特徴:ナレッジパイプラインとプラグインエコシステム
Dify標準RAGの肝は「ナレッジパイプライン」で、取り込みをブラックボックスにせず“見える・分岐できる・加工できる”ETLに変えます。
従来はPDFを一括アップロードして終わりでしたが、実務ではOCRや要約、メタデータ付与などの前処理を柔軟に挟めないと品質が安定しないからです。
DifyではIf-elseやCode、LLMノードを取り込み途中に差し込み、ファイル種別でのルーティングや要約・タグ抽出を自動化できます(参考: Introducing Knowledge Pipeline)。
データソースはPDFやExcelに加え、Google Drive、Confluence、Notion、Webクロールなどを単一のナレッジベースに統合でき、既存のベクトルDB(例: TiDB Vector)とも連携可能です(参考: Dify x TiDB)。
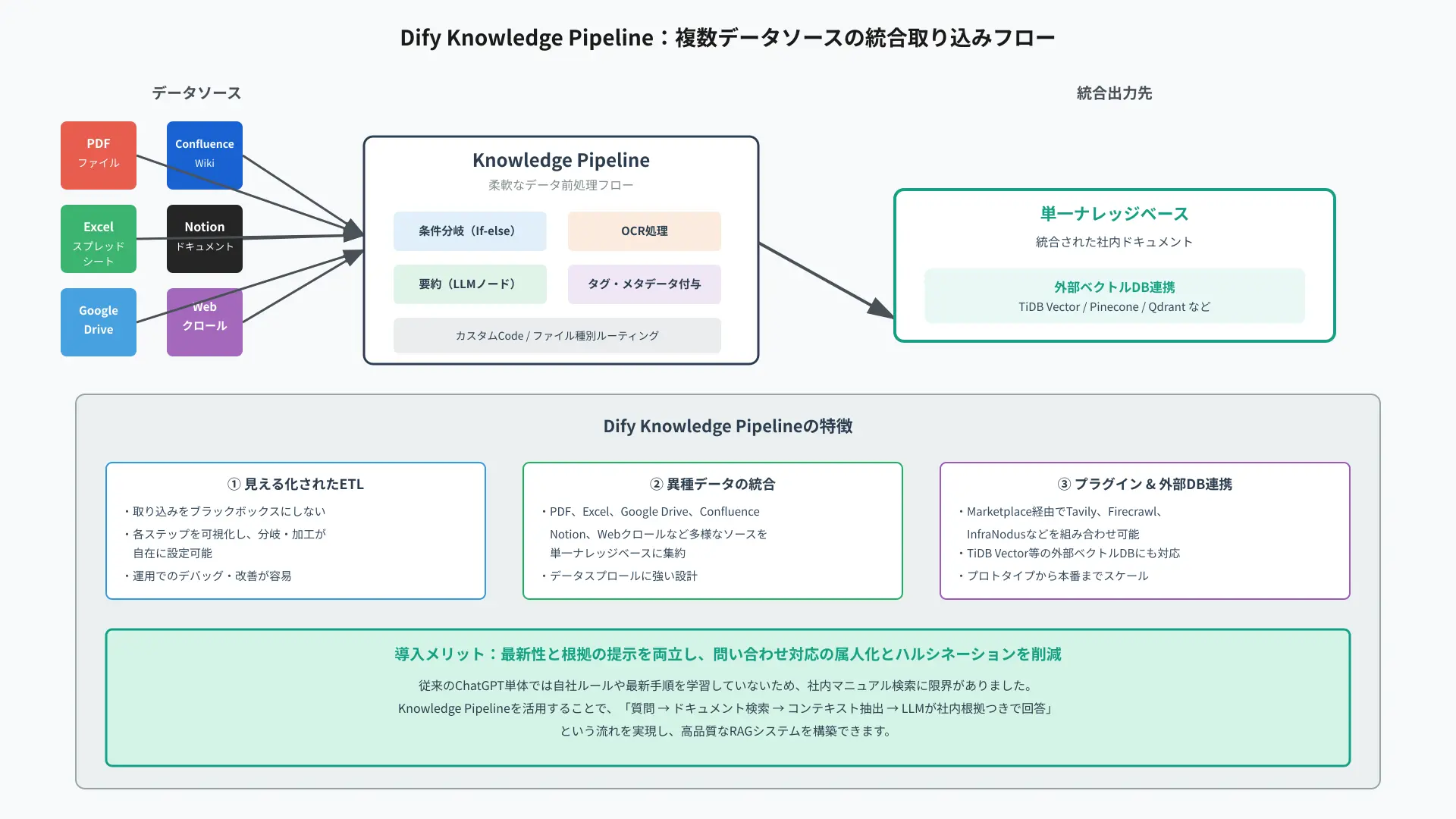
さらにMarketplaceのプラグインでTavilyやFirecrawlのライブWeb取得、InfraNodusのグラフRAGなどを組み合わせ、データスプロールに強いRAGを構築できます(参考: Introducing Dify Plugins)。
“異種データを運用でつなぐ”という発想こそ、プロトタイプから本番までスケールするDify RAGの最大の価値です。
参考:
- Dify Blog: Introducing Knowledge Pipeline
- Dify Blog: Introducing Dify Plugins
- Dify x TiDB: Distributed Vector Storage
どの導入形態を選ぶべきか:クラウド版かセルフホストかを5分で判断する
当セクションでは、Difyの導入形態を5分で判断するための基準と具体的な比較ポイントを解説します。
なぜなら、RAG検証はスピードが命である一方で、ライセンス条件や運用負荷を見誤ると手戻りが大きくなるからです。
- Difyの4つの導入モデル:クラウド/コミュニティ/プレミアム/エンタープライズ
- 中小企業の社内ナレッジ活用なら、まずはクラウド版が現実解
- セルフホスト版を検討すべきケースと、ライセンス上の注意点
Difyの4つの導入モデル:クラウド/コミュニティ/プレミアム/エンタープライズ
結論: 4つの導入モデルは「手軽さ・コントロール・商用化権」の優先度で選べば、5分で迷わず決まります。
理由は、Difyがクラウド、コミュニティ、プレミアム、エンタープライズの4階層で異なる権限と運用負荷を設計しているからです。
まずは全体像をつかむために、導入モデル比較の早見図と要点表を確認してください。
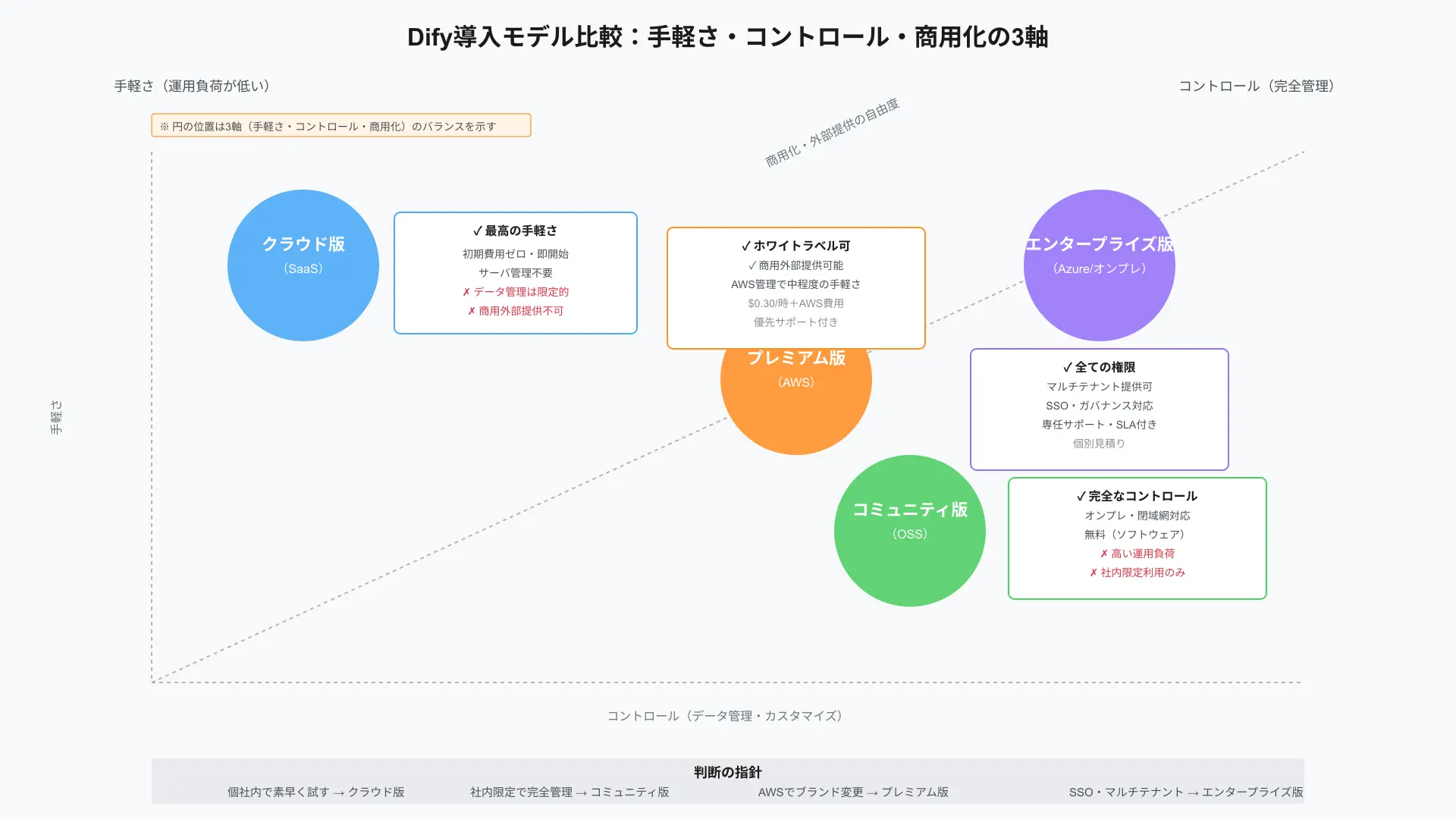
プレミアム版はソフトウェア料に加えてAWSのインフラ費用が別途かかる点も見落としやすい注意点です。
価格やRAG上限の最新詳細は公式のプランページと各マーケットプレイスを必ず確認してください(詳細比較はDifyの料金プランを徹底比較も参照ください)。
判断に迷ったら「個社内で素早く試す=クラウド」「社内限定で完全管理=コミュニティ」「AWSでブランド変更とサポート=プレミアム」「SSOやマルチテナント=エンタープライズ」と整理すると決まります。
| モデル | 運用の手軽さ | デプロイ | 価格の考え方 | マルチテナント(自社提供) | ブランディング | 商用提供(外部) | 公式サポート | 代表用途 |
|---|---|---|---|---|---|---|---|---|
| クラウド(SaaS) | 最高 | cloud.dify.ai | 月額/ワークスペース | — | 不可 | 不可 | プランに準ずる | PoC、社内チャットボット試行 |
| コミュニティ(OSS) | 低 | セルフホスト(Docker等) | 無料(ソフトウェア) | 不可(ライセンス制限) | 不可 | 内部利用のみ可 | コミュニティ | 社内限定・完全管理 |
| プレミアム(AWS) | 中 | AWS EC2 | $0.30/時+AWS費用 | シングルテナント想定 | 可能 | 可能(契約条件による) | 優先メール | AWSでの支援+ホワイトラベル |
| エンタープライズ(Azure/On-Prem) | 中 | Kubernetes/オンプレ | 個別見積り | 可能 | 可能 | 可能 | 専任・SLA | SSO/ガバナンス/大規模提供 |
- 参考: Plans & Pricing – Dify
- 参考: AWS Marketplace: Dify Premium
- 参考: Dify Enterprise – Microsoft Marketplace
- 参考: Dify Open Source License
中小企業の社内ナレッジ活用なら、まずはクラウド版が現実解
結論: 社内ナレッジ活用のPoCなら、cloud.dify.aiのSandboxかProfessionalから始めるのが最短です。
初期費用ゼロでサーバ管理が不要なため、実験速度が上がり意思決定までのリードタイムを短縮できます。
RAGの「ドキュメント数・ストレージ・レート制限」はPoC規模に十分で、優先処理が必要ならProfessionalへの段階的拡張で対応できます。
以下の上限を目安に、まずは社内資料を限定投入して回答品質の基礎検証を行ってください(出典: Plans & Pricing – Dify)。
| プラン | 月額(目安) | ナレッジドキュメント数 | ナレッジストレージ | RAG リクエスト/分 | メッセージクレジット |
|---|---|---|---|---|---|
| Sandbox | 無料 | 50 | 50MB | 10 | 200(初回) |
| Professional | $59 | 500 | 5GB | 100 | 5,000/月 |
| Team | $159 | 1,000 | 20GB | 1,000 | 10,000/月 |
- Sandbox: まずは10〜30名規模の評価
- Professional: 部門内PoCや限定公開
- Team: 全社トライアルや高頻度QA
最初からオンプレや独自ベクトルDBを自前構築する過剰設計は避け、成果が出たら段階的に拡張する方がコスト効率は高くなります。
RAG検証のベストプラクティスはRAG構築のベストプラクティスと、無料枠の活用ポイントはDify無料でできることを参照すると迷いません。
セルフホスト版を検討すべきケースと、ライセンス上の注意点
結論: コミュニティ版は「社内限定利用」が前提で、外部向けSaaSやホワイトラベルには使えません。
Dify Open Source LicenseはApache 2.0ベースですが、マルチテナント提供の禁止とロゴ削除不可という追加条件があるためです。
検討が妥当なのは、厳格なデータ保護や閉域・オンプレ要件、既存のKubernetes基盤が整い社内完結で運用したいケースです。
許されること/禁止されることの早見図を確認し、必要に応じて商用ライセンスへの切替を前提に計画しましょう。
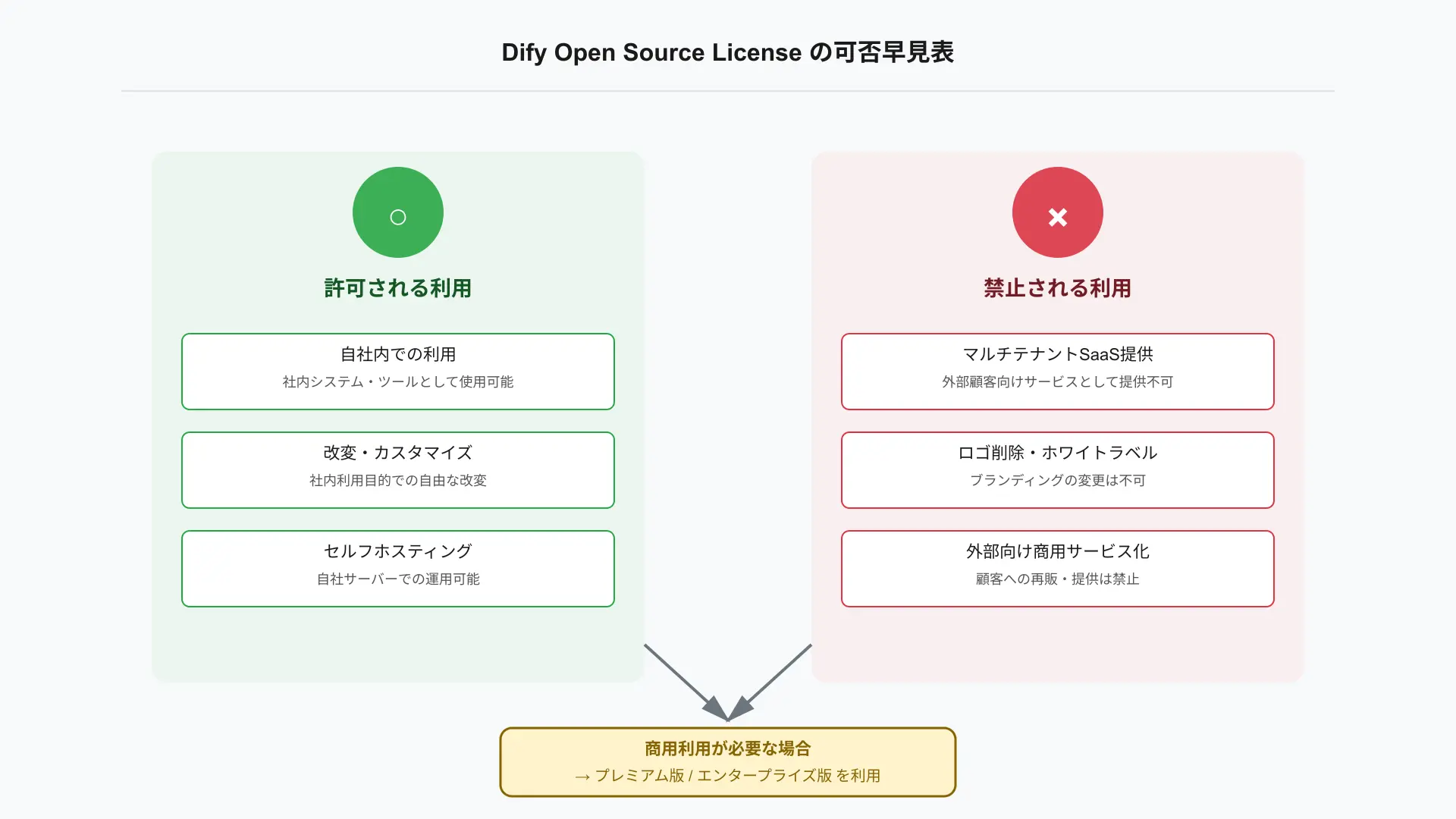
SIやコンサルが外部提供サービスに組み込む場合は、ブランディングやマルチテナントを含む権利が必要になるため、AWSのプレミアム版またはエンタープライズ版が前提になります。
本項は一般的情報であり法的助言ではないため、契約前に公式情報を確認し社内法務と相談してください(深掘りはDifyの商用利用ガイド、オンプレ導入はローカル導入ガイド、セキュリティはセキュリティ徹底解説が参考になります)。
- 参考: Dify Open Source License
- 参考: GitHub Issue: ローカル版の利用制限
- 参考: AWS Marketplace: Dify Premium
- 参考: Dify Enterprise – Microsoft Marketplace
DifyでRAGチャットボットを作る実践手順:ノーコード寄りステップバイステップ
当セクションでは、DifyでRAGチャットボットをノーコード寄りに構築する実践手順を解説します。
なぜなら、Difyの視覚的な「ナレッジパイプライン」により、非エンジニアでも短時間で社内データに根差したボットを作れるからです。(参考: Introducing Knowledge Pipeline – Dify Blog)
- 全体像:ナレッジベース作成→ナレッジパイプライン設定→RAGアプリ→テスト
- ステップ1:ナレッジベースを作成し、PDF・Excel・社内Wikiを登録する
- ステップ2:ナレッジパイプラインでチャンク化・埋め込み・前処理を視覚的に設計
- ステップ3:RAGチャットボットアプリを作成し、ナレッジベースを接続する
- ステップ4:実際の社内マニュアル・FAQでテストし、想定質問リストで検証する
全体像:ナレッジベース作成→ナレッジパイプライン設定→RAGアプリ→テスト
RAG構築は「4ステップ」に絞ると、1日でプロトタイプまで到達しやすくなります。
最初は範囲を「ある部署のFAQ・マニュアルのみ」に限定し、成功体験を積むことが品質と速度の両立に効きます。
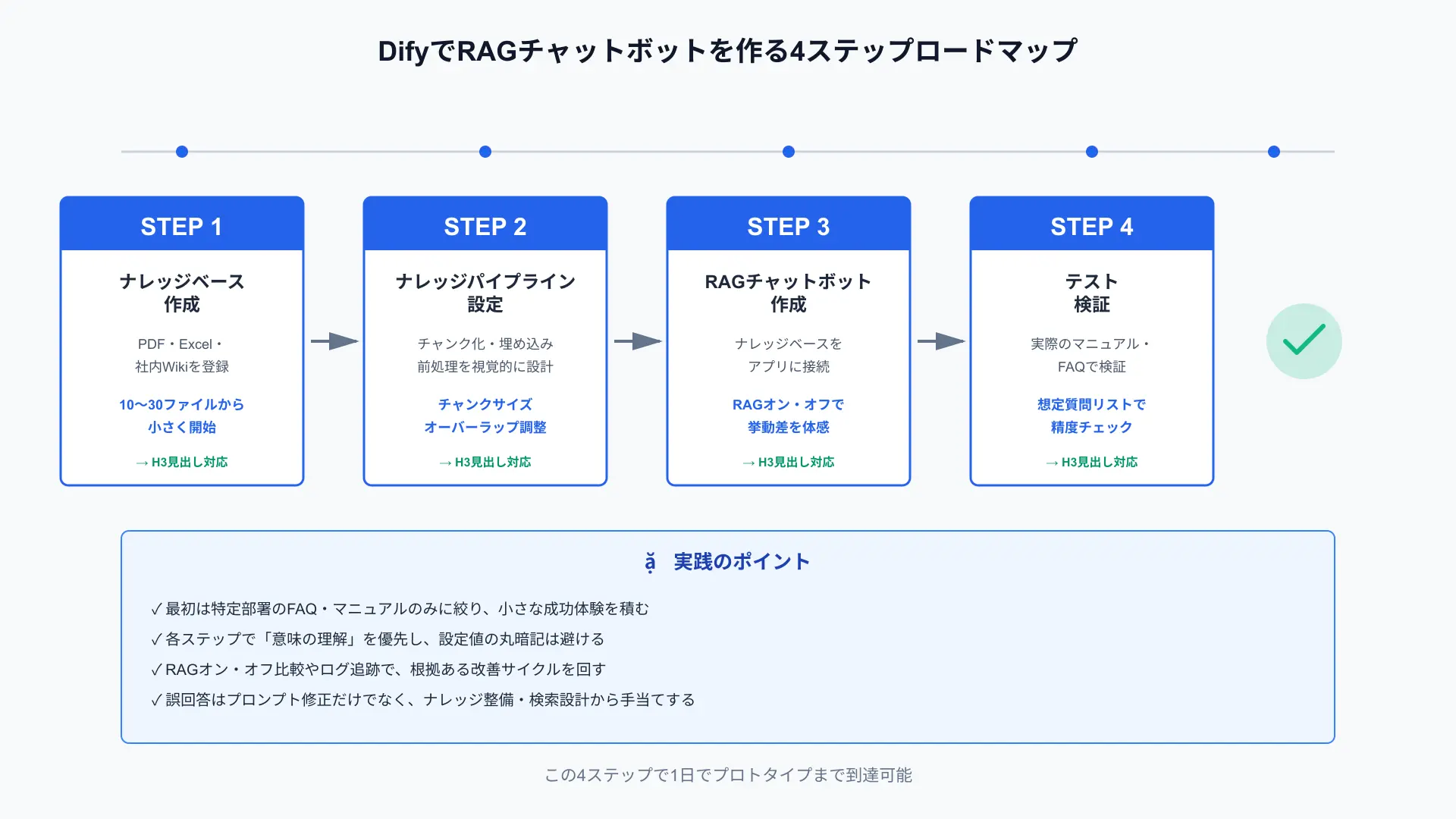
流れは「1. ナレッジベース作成」「2. ナレッジパイプライン設定」「3. RAGアプリ作成」「4. テスト検証」に整理します。
この段取りはDifyが提唱するビジュアルなRAG ETLの思想と合致し、チームでの認識合わせにも有効です。(参考: Introducing Knowledge Pipeline – Dify Blog)
まずはこの4つの箱だけを動かすと決めると、要件のブレを防ぎ、学習コストも最小化できます。
ステップ1:ナレッジベースを作成し、PDF・Excel・社内Wikiを登録する
Difyコンソールで新規ナレッジベースを作り、最初は小さく10〜30ファイルに絞って取り込むのが最短ルートです。
ローカルのPDF・Word・Excel・PPT・Markdownに加え、Google DriveやOneDrive、Notion、Confluenceなど主要ソースを同一ベースに束ねられます。(参考: Introducing Dify Plugins – Dify Blog)
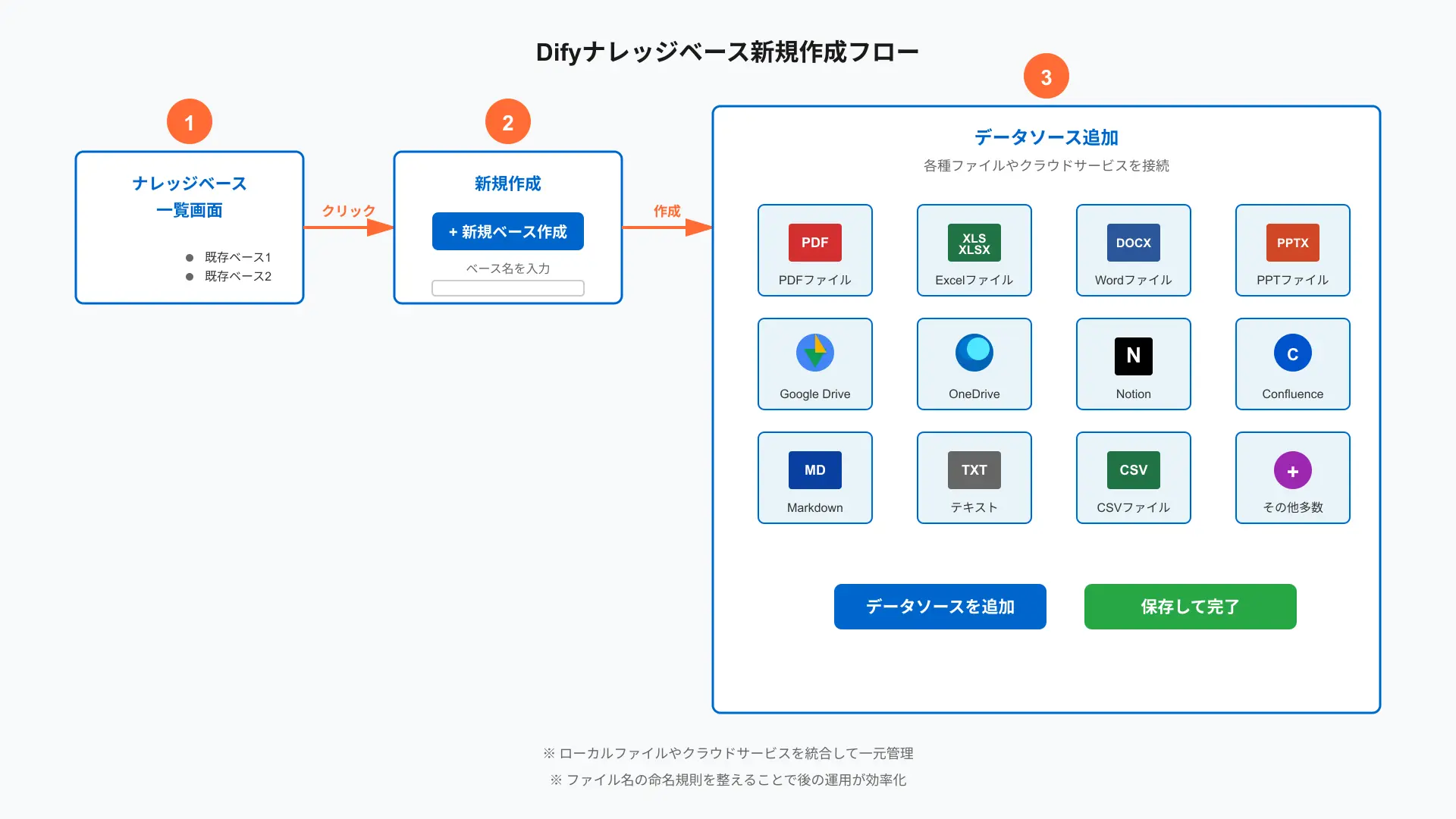
私のプロジェクトでは社内規程PDFを一括投入した際に命名ルールがバラバラで、後からメタデータ付与とフィルタ設計に想定以上の時間がかかりました。
取り込み前に「部門_業務_版_日付」のような命名とフォルダ構成を整えると、パイプラインでも後段のアクセス制御でも効きます。(参考: Knowledge Pipeline Plugin Ecosystem – Dify Blog)
料金やクラウド上限を踏まえた初期スコープ設計は、導入計画の失敗を防ぎますので、上限値は事前に確認しておきましょう。(参考: Plans & Pricing – Dify/関連: Difyの使い方・機能・料金を徹底解説)
ステップ2:ナレッジパイプラインでチャンク化・埋め込み・前処理を視覚的に設計
パイプラインでは「チャンクサイズ・オーバーラップ・埋め込みモデル」を意味で理解して調整することが要です。
チャンクは「検索対象の最小単位」で、サイズは文脈の塊の大きさ、オーバーラップは前後のつながりを持たせる安全マージンだと捉えると迷いません。
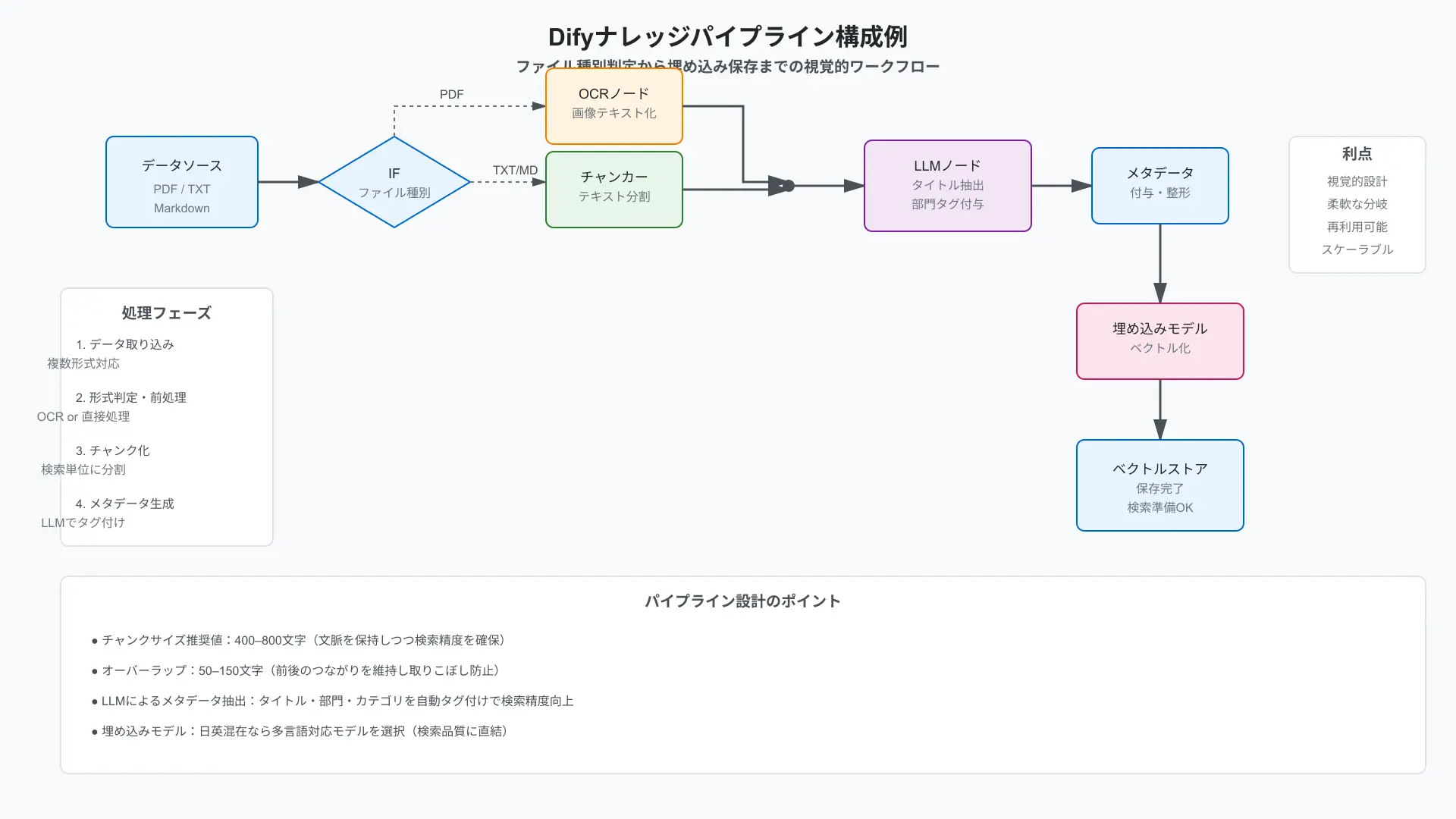
たとえば「IF ファイル種別==PDF→OCR」「テキストは通常チャンカー」「LLMでタイトルと部門タグ抽出→メタデータ付与」という分岐をドラッグ&ドロップで組めます。(参考: Introducing Knowledge Pipeline – Dify Blog)
検索精度が伸びない時は、チャンクを小さめにしてオーバーラップを増やし、親子検索やキーワード検索とベクトル検索をブレンドする「ハイブリッド検索」を有効にし、メタデータフィルタを併用することで劇的に改善します。2026年現在、特定の型番や専門用語の完全一致にはキーワード検索(BM25)、文脈理解にはベクトル検索を組み合わせるハイブリッド検索と、検索結果をLLMに渡す前に並び替える「Rerank(再ランキング)」モデルの併用がRAG構築のデファクトスタンダード(標準構成)となっています。(参考: Dify x TiDB – Dify Blog/Dify Blog)
大規模運用を見据える場合は分散型ベクトルストア連携も選択肢になり、後からスケールさせる余地を確保できます。(参考: Dify x TiDB – Dify Blog)
- 目安設定例: チャンクサイズ 400–800字、オーバーラップ 50–150字、埋め込みは日英混在なら多言語モデル。
- 表や数値中心の資料は小さめチャンクで取り逃しを防止。
- 規程や契約書は大きめチャンク+オーバーラップ厚めで条文の脈絡を保持。
ステップ3:RAGチャットボットアプリを作成し、ナレッジベースを接続する
まずは1つのナレッジベースだけを接続し、RAGのオン/オフを切り替えて挙動差を体感するのが定石です。
テンプレートからチャットボットを作成し、先ほどのナレッジベースをRAGソースとして紐づければ準備は完了です。(参考: Dify: Leading Agentic Workflow Builder)
RAGなしでは一般的な回答に留まり、RAGありでは社内規程の条文を引用しながら根拠を示すなど、信頼性の違いが明確に分かります。
この比較をステークホルダーに見せると投資対効果の議論がしやすく、導入意思決定の後押しになります。
モデルや温度設定を変える前に、まずはRAG配線と検索の手応えが出ているかを点検するのが効率的です。(関連: RAG構築のベストプラクティス)
運用前のこの小さなAB比較が、後の誤回答や説明責任のリスクを大きく減らします。
ステップ4:実際の社内マニュアル・FAQでテストし、想定質問リストで検証する
全社公開の前に、想定質問リストで「正確さ・引用元・トーン」を小人数で厳密にチェックします。
人事や総務のFAQなら「有給の申請締切」など日常的な質問で、回答の根拠とリンク表示が妥当かを検証します。
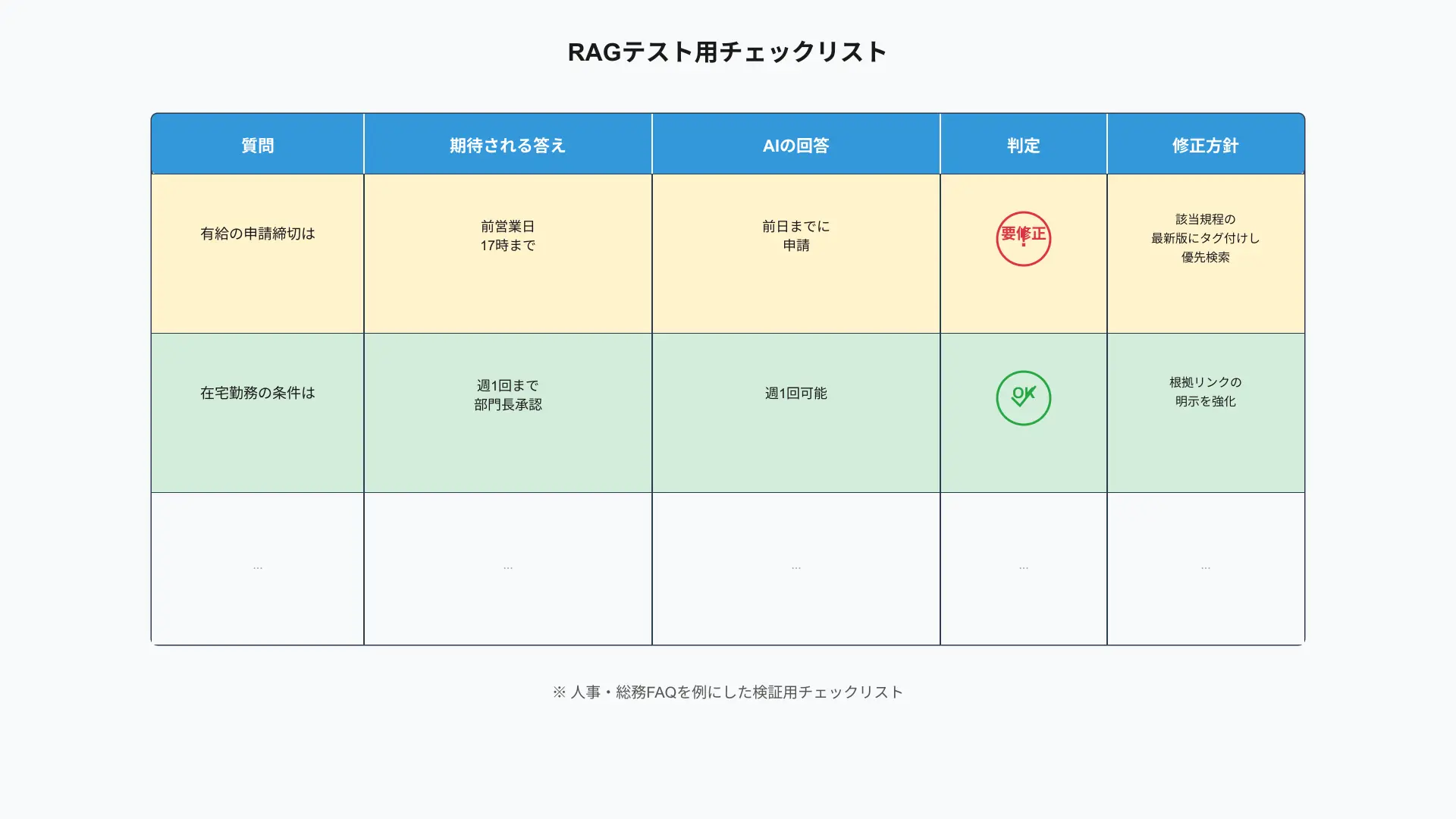
ログを見てどのナレッジがヒットしたかを追跡し、外したクエリはメタデータやチャンク設計の見直しで潰します。(参考: Dify: Leading Agentic Workflow Builder)
誤回答が出た際はプロンプト修正だけに頼らず、ナレッジの整備や検索制約で原因から手当てするのが再発防止の近道です。(関連: AIハルシネーション対策の決定版ガイド)
体系的に学びながら運用体制を整えたい場合は、自社の実務データを用いたハンズオントレーニング(参考: 「自社専用AI定着パッケージ」)でチーム育成を進めると開発と導入の内製化が加速します。
| 質問 | 期待される答え | AIの回答 | 判定 | 修正方針 |
|---|---|---|---|---|
| 有給の申請締切は | 前営業日17時まで | 前日までに申請 | 要修正 | 該当規程の最新版にタグ付けし優先検索 |
| 在宅勤務の条件は | 週1回まで部門長承認 | 週1回可能 | OK | 根拠リンクの明示を強化 |
ナレッジ取り込みのベストプラクティス:PDF・Excel・Wikiを“RAG向けデータ”に整える
当セクションでは、社内のPDF・Excel・WikiをDifyのRAGに最適化して取り込むための実践手順と編集ルールを解説します。
理由は、RAGの回答品質はモデル性能だけでなく、前処理と文書構造の設計に大きく左右され、Difyの「ナレッジパイプライン」を活かす準備ができているかでPoCの成否が決まるからです。
- RAGに向いたドキュメント構造とは?見出し・段落・表を意識する
- PDF・Word・Excel・PPTをDifyに読み込ませるときのコツ
- クラウドストレージ・オンラインWikiとの連携:更新運用まで見据えた設計
- Webサイト・外部情報を組み込むときの注意点(著作権・最新性)
RAGに向いたドキュメント構造とは?見出し・段落・表を意識する
結論は、RAGでは構造が精度を決めるため、見出しレベルで内容を完結させ、段落は短く、表には近接した解説文を付ける編集が必須です。
理由は、検索がチャンク単位で行われるため、長大な段落や表のみのチャンクはヒットしても文脈が欠落し、根拠提示が弱くなるからです。
具体策として、長文マニュアルをそのまま投入せず、PoCではFAQ形式や「1トピック1ファイル」へ小分けしてから取り込みます。
Difyの親子検索は小チャンクの一致に親チャンクで文脈補強できますが、元文書の粒度が粗いと効果が限定的です(参考: Dify Blog)。
まずは「見出し完結」「短段落」「表+近接解説」の三原則で下ごしらえし、次に分割戦略を適用すると早く安定します。
| Before(長文マニュアル) | After(FAQ/1トピック1ファイル) |
|---|---|
| 第3章 勤務規則 全文(20ページ)。見出し内に複数規定が混在。 | FAQ_有給の申請方法.md、FAQ_遅刻・早退の扱い.md などに分割。 |
| 「表1: 休暇コード一覧」だけが独立して掲載。 | 表の直前に「各コードの定義と申請例」を段落で記述して近接配置。 |
| 1段落が8~10行で要点が散在。 | 1段落2~3行に圧縮し、要点を箇条書き併用。 |
設計の背景理解にはRAG全体像の記事も役立ちます(関連: RAG構築のベストプラクティス)。
PDF・Word・Excel・PPTをDifyに読み込ませるときのコツ
結論は、PDFやOffice取り込みは「読み込み前の前処理が9割」で、不要要素の除去と意味付けを先に済ませることです。
理由は、ヘッダ・フッタやページ番号、分割された表罫線がノイズとなり、チャンク品質と埋め込みの一貫性を崩すからです。
私の人事データの実例では、Excelでコード値だけの列を入れたところ『DPT=12』の意味が通じず、部門名列と備考の説明列を追加したところ回答の的中率が大きく改善しました。
Difyのナレッジパイプラインでは取り込み時にLLMノードで要約やメタデータ抽出を自動追加でき、前処理と組み合わせると検索の当たりが安定します(参考: Introducing Knowledge Pipeline – Dify Blog)。
手順はテンプレートの修正→不要行削除→説明列・要約列の追加→取り込み時の自動メタ付与、の順に進めるとミスが減ります。
- PDF: ヘッダ/フッタ/ページ番号を削除し、検索不能な画像PDFはOCRしてから投入。
- Word: 見出しスタイルを正規化し、1段落は2~3行を目安に短く保つ。
- Excel: 1行1レコード、結合セルは避け、意味のあるカラム名+説明列(テキスト)+タグ列を用意。
- PPT: スライドノートに要点解説を記述してからPDF化し、表や図の近くに説明を配置。
Difyの操作全体像は別ガイドが参考になります(関連: Difyの使い方・機能・料金ガイド、リスク設計はAIハルシネーション対策も参照)。
クラウドストレージ・オンラインWikiとの連携:更新運用まで見据えた設計
結論として、クラウドドライブやWiki連携は「対象範囲・アクセス・更新」の3点設計から始めると運用が安定します。
理由は、RAG対象が曖昧だと機密流入やノイズ混入が起こり、再インデックス設計が甘いと最新性が担保できないからです。
DifyはGoogle Drive・OneDrive・Box・Notion・Confluenceなど複数ソースを単一ナレッジベースに束ねられるため、まず「RAG対象フォルダ/スペース」を明確に切ることが重要です(参考: Introducing Knowledge Pipeline – Dify Blog)。
フォルダ構造の例を示します。
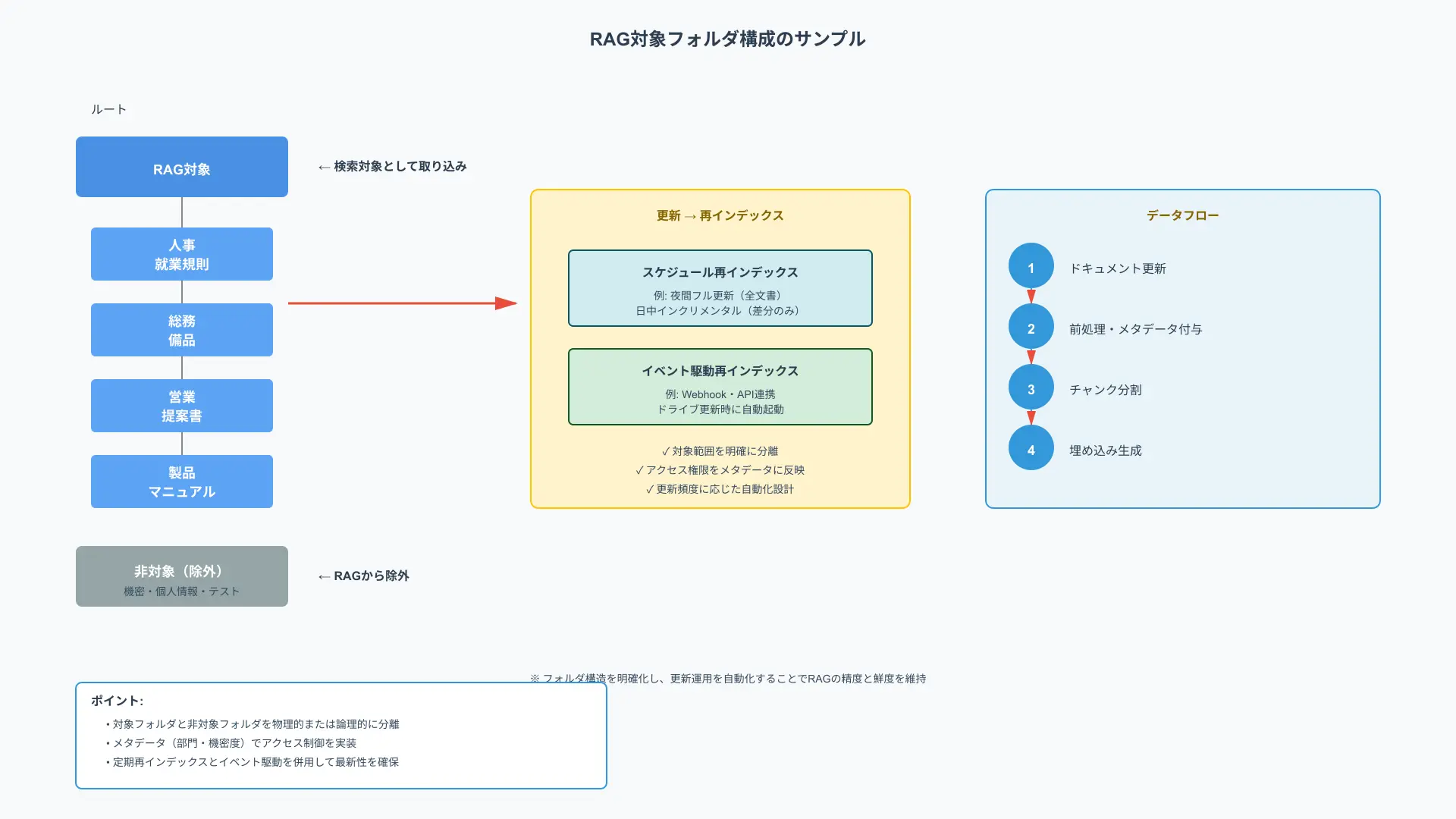
加えて、スペースやページの公開範囲とDify側のメタデータフィルタを整合させ、更新はスケジュール再インデックスやWebhook相当のトリガーで自動化するのが王道です(参考: Dify Blog(メタデータ・フィルタ概説))。
- 対象範囲: /RAG対象/人事/就業規則、/RAG対象/総務/備品 のように「対象」と「非対象」を論理分離。
- アクセス: Wikiの閲覧権限をメタタグ(部門・機密度)に写経し、取得時フィルタで強制。
- 更新: 夜間フル/日中インクリメンタル、または変更イベントでパイプラインを起動。
Webサイト・外部情報を組み込むときの注意点(著作権・最新性)
結論は、Web取り込みは「法務リスクと鮮度リスクの両にらみ」で最小限から始めることです。
理由は、自社サイトでも料金・仕様ページは更新頻度が高く、外部サイトでは著作権や利用規約への適法性確認が不可欠だからです。
TavilyやFirecrawl連携で社内FAQや製品ページを自動クロールできますが、範囲はサブディレクトリ単位に限定し、差分クロールと定期再収集を併用します(参考: Dify x Tavily)。
著作権・引用・robots等の方針は各サイトのポリシーを確認し、詳細判断は必ず自社の法務・顧問弁護士に確認します。
- 参考: 文化庁|著作権(公式)
- 参考: Dify x Tavily(公式ブログ)
最新性が問われる料金・時刻表・在庫ページはRAGに直入れせずツール呼び出しやWeb検索に委ねる分離設計も有効で、あわせてAIハルシネーション対策とRAG設計のベストプラクティスを適用します。
チームの基礎力底上げやRAGデータの整備方針を設計するためには、汎用の学習プログラムではなく、自社の文書構造に最適化した実務指導研修の導入が効果的です。
Dify RAGの精度を上げる設定と運用のコツ:チャンク・検索・プロンプト・メタデータ
当セクションでは、DifyのRAG精度を高めるための具体的な設定と運用の勘所を、チャンク設計・検索パラメータ・プロンプト・メタデータ・ワークフローの順に解説します。
なぜなら、RAGの品質はモデル選定だけでなく、前処理から検索、プロンプト、権限制御までの総合設計に大きく依存し、設定の小さな差が回答の正確性や信頼性に直結するからです。
- チャンクサイズと検索数をどう決める?“読み物系”と“ルール系”で変える
- 親子検索・スコアしきい値・再ランキングなどの検索設定
- プロンプト設計:RAG前提のシステムプロンプトで“引用と根拠”を必ず出させる
- メタデータとフィルタで“部門別・機密区分別”に絞り込む
- ワークフロー機能とRAGの組み合わせ:前処理・後処理で業務ロジックを実装
チャンクサイズと検索数をどう決める?“読み物系”と“ルール系”で変える
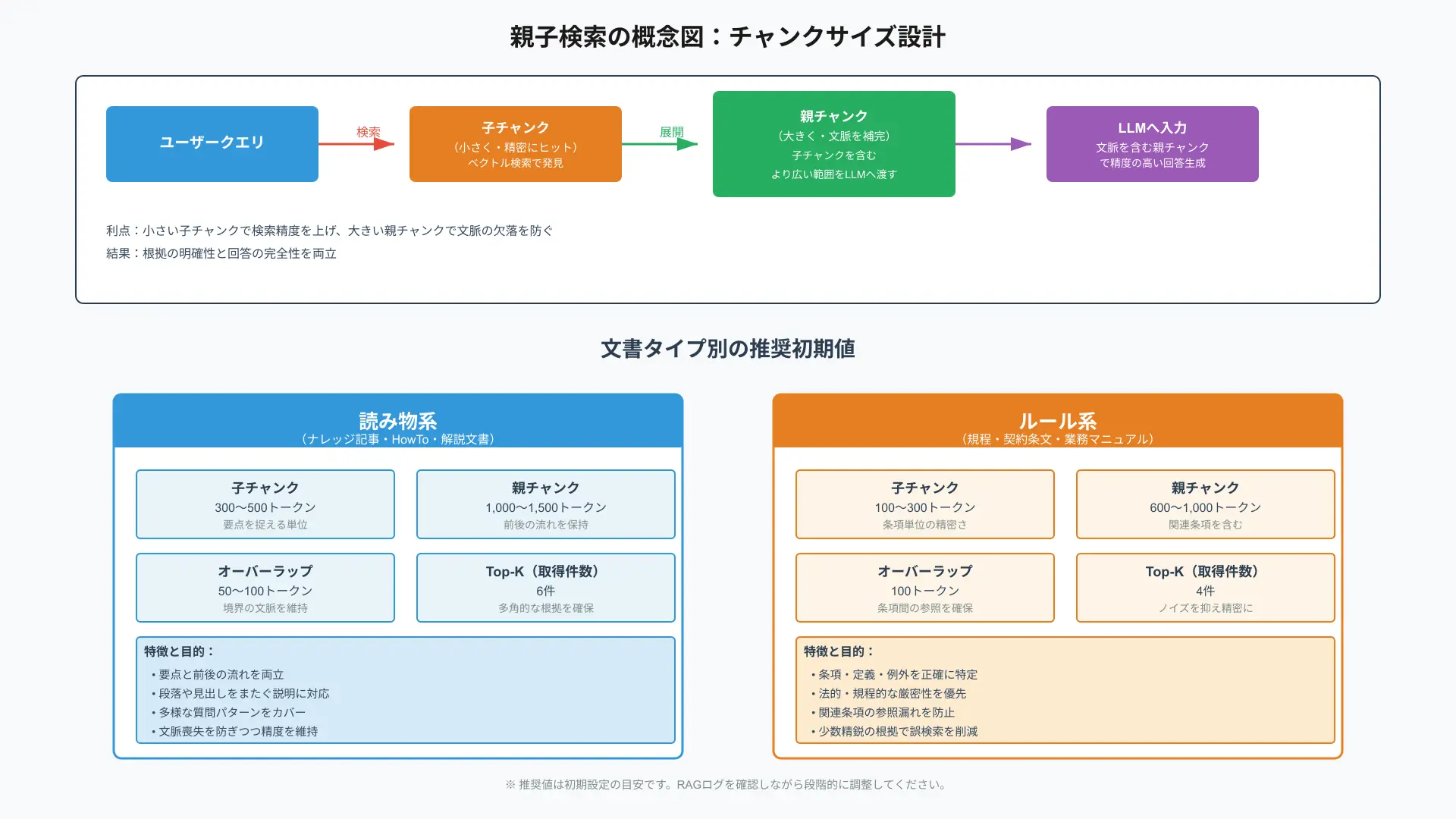
結論は「まずは短めの子チャンク+親子検索で文脈を補い、RAGログを見ながら微調整」がおすすめです。
大きすぎるチャンクは関係ない文まで拾ってノイズが増え、小さすぎるチャンクは定義や前提が切れて文脈喪失を招くため、文書の性質ごとに最適化が必要です。
読み物系(ナレッジ記事・HowTo)は子チャンク300〜500トークン、親1,000〜1,500トークン、オーバーラップ50〜100、K=6を起点にすると要点と前後の流れを両立しやすいです。
ルール系(規程・契約条文)は子100〜300トークン、親600〜1,000トークン、オーバーラップ100、K=4を起点にすると条項単位の精密さを確保しやすいです。
Difyの取得ログで「どのチャンクが引用されたか」「意図に合う根拠が拾えているか」を確認し、Kやオーバーラップ、親子のサイズを段階的に調整します。
親子検索の考え方とパイプライン全体の見える化はDify公式の機能解説が参考になります。
- 参考: Introducing Knowledge Pipeline – Dify Blog
- 参考: v2.0.0-beta.1 – Orchestrating Knowledge, Powering Workflows · Discussion
親子検索・スコアしきい値・再ランキングなどの検索設定
検索は「Kは控えめに始めて上げる」「しきい値は高すぎず低すぎず」「必要に応じて再ランキングで上澄み」を基本にすると安定します。
K(取得件数)を上げすぎるとノイズが混ざりやすく、下げすぎると根拠不足になるため、まずK=4〜8で様子を見るのが現実的です。
類似度スコアのしきい値は下げすぎると無関連の断片が混入するため、初期は0.2〜0.3程度から調整すると安全域を確保しやすいです。
再ランキングはトップ候補の順序を問い直す工程で、曖昧クエリや同義語が多い領域で「関連の強い根拠」を上位に押し上げるのに有効です。
評価は「曖昧な質問」「逆引き」「非対象領域の質問(不明判定)」などの検証セットを用意して、安定性と再現性で比較します。
初期設定の目安は下表をたたき台にして、RAGの利用ログを見ながらK→しきい値→再ランキングの順に影響度を確認すると迷いにくいです。
| 項目 | 推奨初期値 | 調整の目安 |
|---|---|---|
| Top-K(取得件数) | 4〜8 | 根拠不足なら+2ずつ増、ノイズ増なら-2 |
| 類似度スコアしきい値 | 0.2〜0.3 | 無関連混入なら上げる、取り逃しなら下げる |
| 親子検索 | 有効 | 子は短く、親で文脈補完を徹底 |
| 再ランキング | 必要時オン | 曖昧クエリや同義語が多い領域で有効 |
プロンプト設計:RAG前提のシステムプロンプトで“引用と根拠”を必ず出させる
RAGでは「役割定義・根拠の明示・不明時の沈黙」をシステムプロンプトに明文化し、監査性と信頼を担保します。
具体的には「あなたは◯◯部門向けFAQボット」などのロールに加え、「回答末尾に引用元ドキュメント名とセクションを必ず記載」「不明なら推測せず不明と答える」を必須ルールにします。
また「検索で取得した文書以外の一般知識に頼らない」「日本語で簡潔に、箇条書き優先」などの書式・範囲制約を加えるとハルシネーションが抑制されます(関連解説: AIハルシネーション対策の全手法)。
プロンプトは下記テンプレートを起点にし、業務ごとの禁止事項や優先ルールを追記して運用します。
プロンプトの基本は汎用理論も有益なので、要点を学ぶ際は解説記事も参考にしてください(参考: プロンプトエンジニアリング入門)。
【ロール】
あなたは人事部向けの社内規程FAQボットです。最新の社内ナレッジベースに基づき、正確で簡潔な回答を行います。
【厳守ルール】
- 検索で取得したコンテキストの範囲内でのみ回答する。
- 不明な場合は推測せず「不明です。該当する規程が見つかりませんでした。」と答える。
- 回答末尾に「出典:ドキュメント名/セクション(ページ)」を必ず記載する。
- 日本語で丁寧に、箇条書きを優先し、最初に要点、次に補足を書く。
【回答フォーマット】
1) 要点
2) 詳細(箇条書き)
---
出典:<ドキュメント名A セクション/ページ>、<ドキュメント名B セクション/ページ>
RAGの設計やプロンプトエンジニアリングを体系的に学ぶには、自社の実務課題をそのまま教材としてカスタマイズ開発と教育を同時に行う研修パッケージを利用するのが近道です。
メタデータとフィルタで“部門別・機密区分別”に絞り込む
メタデータでアクセス対象を事前に絞ると、精度とセキュリティを同時に引き上げられます。
ドキュメントに「department」「doc_type」「confidentiality」などのタグを整備し、ユーザー属性に応じて検索対象を動的に制限します。
たとえば人事の社員はHRナレッジを優先し、アルバイトにはPublicまたはInternalのみを返すなどの制御が可能です。
Difyはメタデータによるフィルタを公式にサポートしており、権限制御と検索効率化の両面で有効です(出典: Dify Blog)。
設計・運用の全体像を掴むにはセキュリティ観点の整理も重要なので、合わせて解説を参照してください(参考: Difyのセキュリティ徹底解説)。
以下はフィルタ条件の疑似コード例です。
# メタデータ設計例
# keys: department, doc_type, confidentiality
# フィルタ条件例(人事部ユーザー)
department == "HR" AND confidentiality IN ["Public", "Internal"]
# フィルタ条件例(アルバイト)
confidentiality == "Public" AND doc_type IN ["manual", "faq"]
ワークフロー機能とRAGの組み合わせ:前処理・後処理で業務ロジックを実装
Difyのビジュアルワークフローで「前処理の分類→KB切替→RAG→後処理整形」をつなぐと、コード最小で高度な業務要件を満たせます。さらに2026年のトレンドとして、単発の検索ではなくLLM自身が検索クエリを動的に修正しながら推論を繰り返す「Agentic RAG(エージェント型RAG)」や、文書内のエンティティと関係性をグラフ化して複雑な推論を行う「GraphRAG(グラフRAG)」の要素技術も、Difyのビジュアルワークフロー内で柔軟に組み合わせることが可能になっています。
前段で質問意図や業務カテゴリをLLMで分類し、部門別ナレッジベースを選択してからRAGを実行すると、誤検索を大幅に抑制できます。
後段では敬語統一や社内用語変換、引用の体裁付けなどを追加し、利用部門の基準に沿う最終出力へ整えます。
下図のように「質問→分類LLM→RAGノード→回答整形LLM」という直線フローから始め、必要に応じてIf分岐やコードノードを増やします。
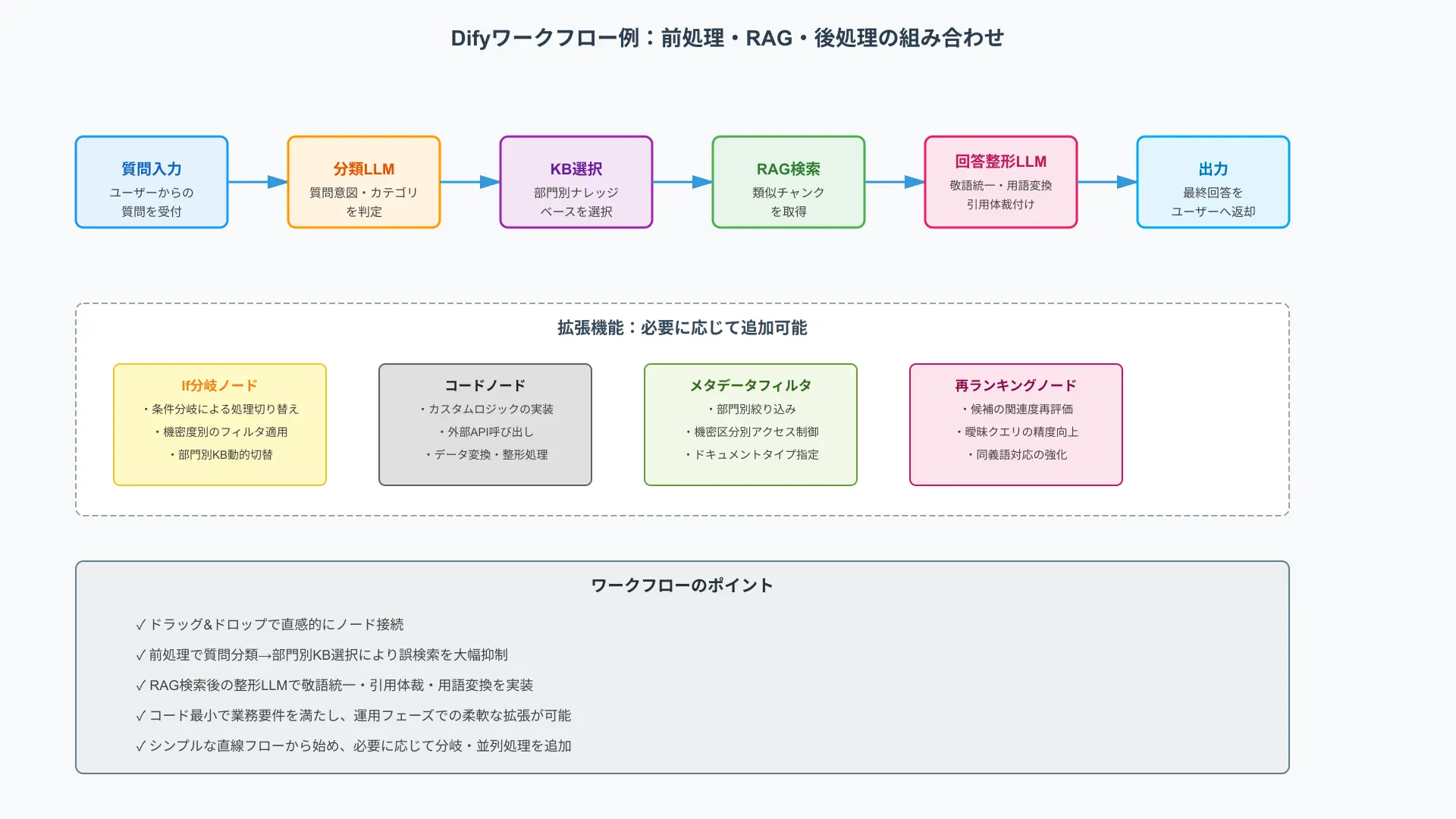
実装イメージは公式のワークフロー解説や事例が参考になります(参考: Deep Research Workflow – Dify Blog、Difyの使い方・機能・料金)。
セキュリティと商用利用の考え方:社内ドキュメントを安心してDifyに載せるために
当セクションでは、Difyを使って社内ドキュメントをRAGに載せる際の「セキュリティ」と「商用利用(ライセンス)」の考え方を実務目線で整理します。
理由は、RAGは情報の扱いが広範に及ぶため、導入形態ごとの前提と運用ルールを明確にしないと、情報漏えい・契約違反・運用停止といった重大なリスクに直結するからです。
- クラウド版利用時に押さえるべきセキュリティ観点
- セルフホスト版利用時のメリット・注意点(ライセンス・インフラ運用)
- 社内ルール・個人情報を含むナレッジの扱い方
クラウド版利用時に押さえるべきセキュリティ観点
結論として、クラウド版を使うなら「Dify本体」と「接続するLLMプロバイダ」のデータ取り扱いを、チェックリストで二重に検証することが必須です。
なぜなら、SaaSはマルチテナントで運用され、RAG処理や推論で第三者のクラウド(例: OpenAI等)にデータが送信され得るため、保存場所・暗号化・アクセス制御・ログ・保持期間の整合性を両面で満たす必要があるからです。
具体的には、次のチェックリストを自社セキュリティポリシーにマッピングして適合性を確認します。
| 観点 | 確認する質問例 | 補足/資料 |
|---|---|---|
| 保存場所と暗号化 | どのリージョンに保存されるか、保存時/転送時暗号化の方式は何か。 | データ主権や業法要件に影響。 |
| アクセス制御・認証 | 権限分離は十分か、SSOやIP制限は可能か。 | EnterpriseではSSO提供(出典: Microsoft Marketplace: Dify Enterprise)。 |
| 監査ログ | 誰が何にアクセスしたかの記録と保持期間、エクスポート可否。 | 監査証跡の有無は内部統制に直結。 |
| モデル提供先への送信 | OpenAI等への送信有無、送信抑止/匿名化、プロバイダ側の学習利用有無。 | プロバイダのデータ利用規約も確認。 |
| データ保持/削除 | 退会・削除リクエスト時の消去SLA、バックアップからの完全削除可否。 | 個人情報保護や委託先管理で重要。 |
| RAGのスケーリング制約 | ナレッジ数/容量/レート制限による業務影響はないか。 | 例: Sandbox 50文書/50MB/10件/分、Professional 500文書/5GB/100件/分、Team 1,000文書/20GB/1,000件/分(参考: Plans & Pricing – Dify)。 |
加えて、Difyの「メタデータを用いたナレッジフィルター」でユーザー権限に応じた取得制御を設計すると、精度とガバナンスを同時に高められます。
関連する一次情報は次を参照してください。
- 料金・制限の詳細(参考: Plans & Pricing – Dify)
- メタデータによるアクセス制御(参考: Dify Blog)
なお、この記事は一般的な情報であり、最終判断は自社の情報セキュリティ部門・法務と必ずご相談ください。
最終的には、チェックリストをもとにクラウドの利便性と社内基準の両立可否を評価し、要件を満たさない場合はセルフホストを検討します。
より詳しい解説は社内向けに整理したDifyのセキュリティ徹底解説や、横断的な論点をまとめた生成AIのセキュリティ完全解説も参考になります。
セルフホスト版利用時のメリット・注意点(ライセンス・インフラ運用)
結論として、セルフホストは「データを自社管理下に置ける」強みがある一方、コミュニティ版のライセンス制約とインフラ運用コストを正しく織り込むことが不可欠です。
理由は、コミュニティ版にはマルチテナント提供の禁止やロゴ改変不可といった追加条件があり、外部顧客向けの提供やホワイトラベル運用には適さないためです。
また、OS/コンテナ/DB/ベクトルストア/バックアップ/監視/アップデートの全レイヤーを自社が担うため、人的コストとダウンタイムリスクのマネジメントが必要です。
判断を容易にするため、次の意思決定フローを参考にしてください。
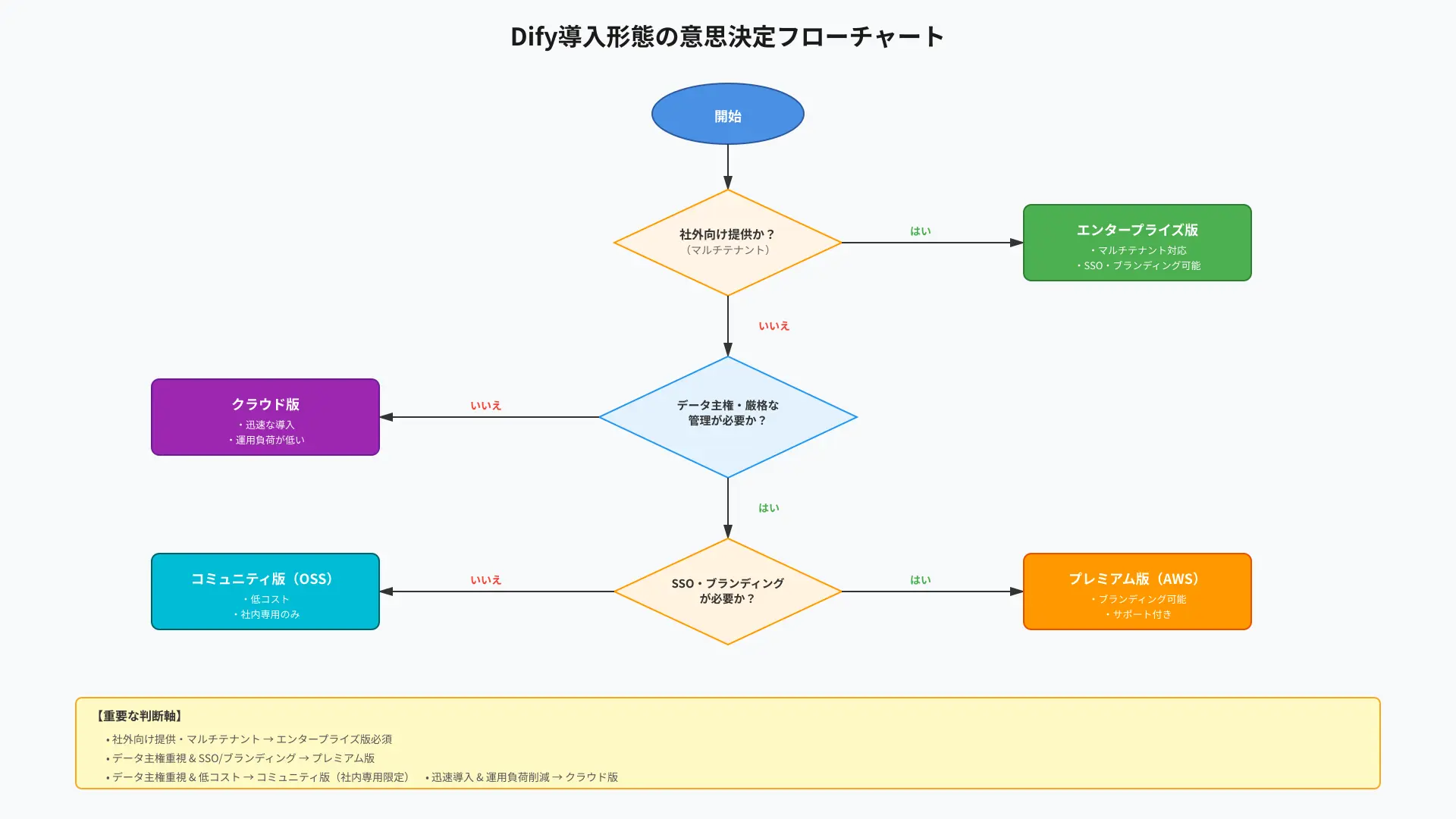
| 導入形態 | おすすめ場面 | 主な権利/制限 |
|---|---|---|
| コミュニティ版(OSS) | 社内専用で低コストに始めたい。 | マルチテナント不可・ロゴ改変不可(出典: Dify Open Source License)。 |
| プレミアム版(AWS) | AWSでサポート/ブランディングが必要。 | EC2上にデプロイ、ブランド変更やサポートが可能(参考: AWS Marketplace: Dify Premium)。 |
| エンタープライズ版 | 社外提供/マルチテナント/SSO/オンプレ必須。 | Kubernetes対応、SSO・マルチテナント等を提供(参考: Microsoft Marketplace: Dify Enterprise)。 |
関連情報として、コミュニティ版の利用制限はGitHubのディスカッションでも再確認できます(参考: Are there any restrictions on the use of the locally deployed version of dify?)。
結局のところ「社内専用」ならクラウド/コミュニティで素早く始め、「社外提供・マルチテナント・SSO・厳格なコンプライアンス」が要件ならエンタープライズ一択です。
社内ルール・個人情報を含むナレッジの扱い方
結論は、RAGに載せる前に「公開レベル別の文書整理」を行い、個人情報・機微情報は除外か匿名化し、権限ベースのアクセス制御を組み合わせることです。
理由は、人事・総務マニュアルや顧客対応ナレッジにはPIIや健康情報などが混在しやすく、無造作に取り込むと漏えいリスクと回答の誤誘導を同時に招くからです。
たとえば、RAGから除外しやすい情報は次の通りです。
- 未公開の個人情報(氏名・住所・社員ID・健康/評価情報等)
- 契約上秘匿すべき第三者情報や法令で厳格管理が求められる情報
- 公開前の経営資料・価格表・ソースコード等の秘匿資産
一方で対象にする場合の工夫は次です。
- 匿名化・仮名化・要約化で可逆性を下げる
- ドキュメントに「部門/機密区分/有効期限」などのメタデータを付与し、Difyのメタデータフィルターで権限に合致する文書のみを検索対象にする(参考: Dify Blog)
- 高秘匿は問合せゲートを分離し、回答はテンプレート化したサマリーに限定
運用ルールとしては「公開レベル別の文書棚卸」「高秘匿は別仕組みで管理」「取り込み前レビュー→定期棚卸→削除」のサイクルを定着させます。
私は資格試験システムの高セキュリティ案件に関わった際、要件定義の最初期にデータ分類と消去SLAを固めたことで、後工程の手戻りと監査指摘を大幅に減らせました。
最終的に、分類→匿名化/要約→権限制御→監査の流れを標準手順にし、必要に応じてRAGの設計自体を見直すのが安全です。
RAGの設計観点はRAG構築ベストプラクティスや、回答品質向上のためのAIハルシネーション対策も合わせて確認すると効果的です。
Difyを用いた本格的なRAG実装やセキュアなナレッジ管理を体系的に学びたい場合は、自社のプライバシーポリシーに即した運用研修を並走させるのが現実的です。
自社ユースケースへの落とし込み:社内FAQ・マニュアル検索・顧客サポートのパターン集
当セクションでは、Dify×RAGの実装を自社の具体ユースケースへ落とし込み、社内FAQ、現場マニュアル検索、顧客サポート公開の3パターンと、ノーコードの限界線を解説します。
なぜなら、初期PoCが失敗しがちな原因の多くは、ナレッジ選定や権限・ライセンスの線引きが曖昧なまま進めてしまうことにあるため、最初に“型”を決めてから作ることが成功の近道だからです。
- 社内FAQボット:人事・総務・ITヘルプデスクから始める
- 業務マニュアル検索:現場の作業手順書をRAG化するときの注意点
- 顧客サポート向けナレッジボット:どこから“商用サービス”になるか
- どこからエンジニアの協力が必要になるか:ノーコードの限界ライン
社内FAQボット:人事・総務・ITヘルプデスクから始める
最初の一歩は人事・総務・ITの社内FAQから着手するのが、精度・運用・インパクトのバランスが最も良い選択です。
この領域はナレッジが比較的整備されており、更新頻度やトーン&マナーも部門で統一しやすいからです。
人事では就業規則PDFや制度ガイド+人事部のQ&Aシート、ITでは社内Wikiとチケット履歴をFAQ化するなど、既存資産をRAG化しやすい土台があります。
アクセス制御はメタデータで部門・機密区分・有効期限をタグ付けしてフィルタする設計にすると、誤った参照を防ぎながら検索精度も上がります(参考: Dify Blog)。
取り込みはDifyのナレッジパイプラインでPDFのOCR分岐や要約・メタデータ抽出をワークフロー化しておくと、更新運用が楽になります(参考: Introducing Knowledge Pipeline – Dify Blog)。
運用のクセはプロンプト内で“社内公式の口調”を明示し、回答の根拠リンクを常に付与するルールにすると、信頼性が担保できます。
| 用途(テンプレ) | 対象ナレッジ | 推奨メタデータ | プロンプト例 |
|---|---|---|---|
| 人事・総務FAQ | 就業規則PDF、福利厚生ガイド、Q&Aスプレッドシート | 部門=HR、機密=Internal、施行日、有効期限、改定版 | 「あなたは人事部の公式FAQ担当です。根拠の条文・ページ番号を必ず示し、原文リンクを付けて回答してください。」 |
| ITヘルプデスクFAQ | 社内Wiki(Confluence等)、過去チケットの解決記録 | システム名、OS/バージョン、最終更新日、重要度 | 「あなたは社内ITサポートです。手順は番号付きで簡潔に提示し、注意点と代替策も1つ示してください。」 |
| 総務(備品・稟議) | 申請マニュアル、稟議テンプレ、固定資産台帳の運用ルール | 申請種別、上限金額、承認フロー、地域/拠点 | 「あなたは総務の窓口です。必要書類と承認経路、締切を箇条書きで案内し、関連フォームのリンクを付与してください。」 |
プロンプトの雛形は次の通りです。
あなたは「社内公式FAQ」担当者です。事実のみを参照し、出典URL/文書名/ページを必ず明記してください。回答は最大300字、最後に“次の一歩(フォームや連絡先)”を提示します。
RAGの実装論点はRAG構築のベストプラクティスや、クラウド上の容量制限を含むDifyの料金プランを事前に確認しておくと設計がぶれません。
業務マニュアル検索:現場の作業手順書をRAG化するときの注意点
現場マニュアルは「1手順=1チャンク」と「見出しの明示」を徹底し、必要に応じて親子検索を併用するのが安定解です。
理由は、工程が飛びやすい長文を粗く分割すると、検索命中しても前後文脈が欠落し、誤手順を誘発しやすいからです。
チャンク前に画像・図表の要点をテキスト補足し、タイトルに工程番号を含めると、検索ヒット後の読解負荷が大幅に下がります。
親子検索を使えば、細かい手順にヒットしつつ、上位の章・セクションで文脈を補完でき、回答の一貫性が向上します(参考: Dify Blog(親子検索の文脈拡張))。
取り込みでは、DifyのナレッジパイプラインにLLMノードを挿入し、「工程タイトル抽出」「危険ポイント抽出」「版数付与」を自動化すると運用が安定します(参考: Introducing Knowledge Pipeline – Dify Blog)。
安全性と精度の観点では、回答に出典セクションと版数を必ず表示し、ハルシネーション対策を平常運転に組み込むのが効果的です(参考: AIハルシネーション対策の全手法)。
- 現場マニュアルのRAG対応チェックリスト
- 1手順=1チャンク(見出し: 工程番号+名称)。
- 画像・図の要点をテキストで補足(OCRや代替テキスト)。
- 版数・改定日・有効期限のメタデータ付与。
- 親子検索を有効化し、上位章で文脈を補完。
- 危険作業は注意喚起テンプレをプロンプトに固定。
- 回答末尾に出典リンクと版数を必ず表示。
- 定期ジョブで差分取り込みと再埋め込みを実行。
セキュリティ要求が高い現場は、権限タグで参照範囲を厳密に絞ると安心です(参考: Dify Blog(メタデータ・アクセス制御)、参考: Difyのセキュリティ徹底解説)。
顧客サポート向けナレッジボット:どこから“商用サービス”になるか
PoC段階では“社内サポート・CS担当の裏側ツール”として運用し、外部公開はライセンスとインフラを整えた段階的スケールで進めるべきです。
理由は、Difyのオープンソース版はマルチテナント運用やブランディング変更に制限があり、外部向け提供は有償ティアが前提になるためです(参考: Dify Open Source License)。
実務では①社内限定の解決支援→②特定顧客グループへの限定公開→③正式な外部サービス化、の順でリスクとコストを段階管理します。
②以降ではブランディングやSLA、スケール要件に合わせ、AWSのPremium版やKubernetes対応のEnterprise版を検討します(参考: AWS Marketplace: Dify Premium、参考: Dify Enterprise – Microsoft Marketplace)。
外部公開前に、料金・ドキュメント容量・レート制限などのクラウド制約も把握しておくと、運用停止リスクを避けられます(参考: Plans & Pricing – Dify)。
ライセンス線引きとコスト設計は、先に社内で合意形成しておくと移行が滑らかです(関連: Difyの商用利用完全ガイド、関連: Difyの料金プラン)。

- 参考: Dify Open Source License(追加条件)
- 参考: AWS Marketplace: Dify Premium
- 参考: Dify Enterprise – Microsoft Marketplace
- 参考: Plans & Pricing – Dify
どこからエンジニアの協力が必要になるか:ノーコードの限界ライン
単一テナントの社内RAGと既存プラグイン範囲の連携までは、基本的にノーコード/ローコードで十分に回せます。
一方で、独自SaaSや基幹DBへのカスタム接続、ローカルLLMのホスティング、SSOやマルチテナント運用は、早めにエンジニアと設計した方が安全です(参考: Introducing Dify Plugins – Dify Blog、参考: Dify Enterprise)。
私のPM経験では、ノーコードで外部APIを連結しまくった結果、誰も触れない“スパゲッティ運用”になり、障害時に全停止するという失敗を経験しました。
その後、権限・ルーティング・監視の責務分担を整理し、プラグイン化とGit管理に切り替えたことで、変更影響の見える化と再現性が劇的に改善しました。
迷ったら「再利用されるか」「監視・権限・テストを自動化できるか」を判断軸にし、該当すればエンジニアへエスカレーションするのが無難です。
開発チームや実務担当者のスキルを底上げし、エンジニアとの円滑な連携体制を築くためには、カスタマイズ型の実地研修(参考: 「自社専用AI定着パッケージ」)を並行して回すのが最適です(比較参考: ノーコードAIアプリ開発の完全比較)。
- ここから先は開発チームに相談するチェックポイント
- 独自SaaS/基幹DBへの双方向連携が必要。
- SSO(SAML/OIDC)や厳格なRBACが必須。
- マルチテナントで顧客データを分離運用したい。
- モデル/埋め込み/ベクトルDBのコストとSLAを最適化したい。
- 監査ログ、CI/CD、負荷試験などのオペレーションを確立したい。
まとめ
本記事では、Difyを用いた社内ナレッジのRAGチャットボットをノーコード寄りに1日でプロトタイプする手順、チャンク分割や親子検索・ハイブリッド検索・メタデータフィルタを駆使した精度調整のベストプラクティス、およびセキュリティとライセンスの注意点について徹底解説しました。
Difyのビジュアルなナレッジパイプラインは、2026年現在主流となっているハイブリッド検索や再ランキング(Rerank)モデルの統合、さらにはAgentic RAGやGraphRAGといった高度なデータ連携までをノーコードで直感的に実装することを可能にしています。
社内の実務マニュアルやFAQなどのナレッジデータを整理し、Difyを使った業務改善プロセスを自律的に開発できるコア人材を社内に効率よく増やしていきたい場合は、研修を伴走型で実務に直結させる次の「自社専用AI定着パッケージ」の活用が極めて有効です。
【成果持ち帰り型3週間】
研修だけで終わらせない!「自社専用AI」定着パッケージ
「社員がAIを使えない」「自社商材に合わない」を解決。講師がその場で実務用にカスタマイズ。月額10万円〜。
次の一歩として、まずはDifyのクラウド版などを活用して10〜30ファイル程度のスモールスコープからナレッジベースを作成し、プロトタイプボットの実際の回答精度をテストしながら、自社の業務に最適な導入ステップとデータ連携の方針を具体化していきましょう。
なお、生成AIを用いたビジネス全体のDXや、ローコード・ノーコード開発をさらに深く学びたい方は、解説書籍である『生成DX』や『生成AI活用の最前線』『生成AI 最速仕事術』もぜひ併せて確認してください。